Disclaimer All information is offered in good faith and in the hope that it may be of use for educational purpose and for Database community purpose, but is not guaranteed to be correct, up to date or suitable for any particular purpose. db.geeksinsight.com accepts no liability in respect of this information or its use.
This site is independent of and does not represent Oracle Corporation in any way. Oracle does not officially sponsor, approve, or endorse this site or its content and if notify any such I am happy to remove.
Product and company names mentioned in this website may be the trademarks of their respective owners and published here for informational purpose only.
This is my personal blog. The views expressed on these pages are mine and learnt from other blogs and bloggers and to enhance and support the DBA community and this web blog does not represent the thoughts, intentions, plans or strategies of my current employer nor the Oracle and its affiliates or any other companies. And this website does not offer or take profit for providing these content and this is purely non-profit and for educational purpose only.
If you see any issues with Content and copy write issues, I am happy to remove if you notify me.
Contact Geek DBA Team, via geeksinsights@gmail.com
|
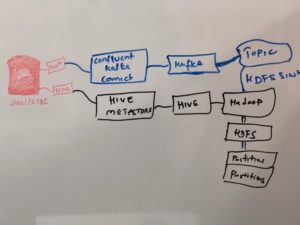
Oracle database which does not need much introduction and as well as Kafka, Kafka has been is a high-throughput distributed message system that is being adopted by hundreds of companies to manage their real-time data. Companies use Kafka for many applications (real time stream processing, data synchronization, messaging, and more). But building ETL with kafka is cumbersome until recently , with Kafka connect which can seemlessly integrated source and target data easily with connectors called Source, Sink connectors.
Kafka connect, is designed to make it easier to build large scale, real-time data pipelines by standardizing how you move data into and out of Kafka. You can use Kafka connectors to read from or write to external systems, manage data flow, and scale the system—all without writing new code. Kafka Connect manages all the common problems in connecting with other systems (scalability, fault tolerance, configuration, and management), allowing each connector to focus only on how to best copy data between its target system and Kafka. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. An export connector can deliver data from Kafka topics into secondary indexes like Elasticsearch or into batch systems such as Hadoop for offline analysis.
Further, not only Kafka can provide stream data pipeline it also can do lot of transformation using inbuilt transformations and complex aggregations using kafka streams. Kafka streams can do event aggregation, complex joins and also provide persistence query streams on top of a stream.
All of these has been presented in my recent Oracle Code One Bengaluru Event on 15-Mar-2019, and the presentation slides are available here.
You can download entire code demo from my git hub repository here
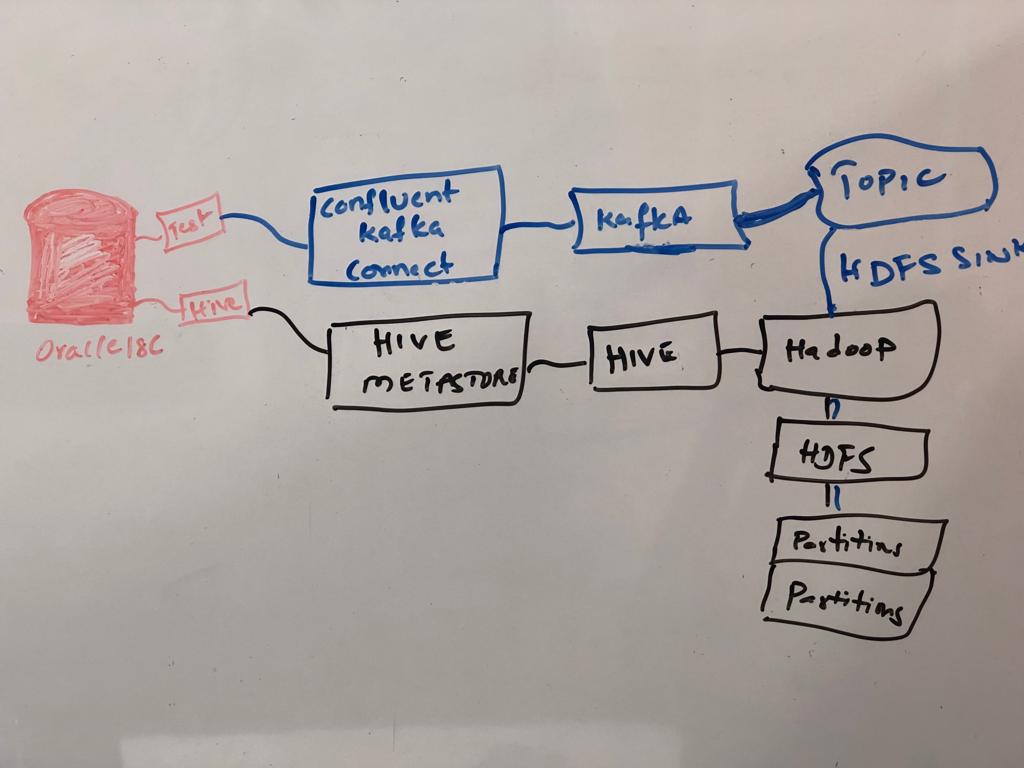
In this video and presentation, I have explored Kafka connect as ETL tool to capture database changes from source to target and how kafka topic is used to deliver the CDC to target systems. For source side I have used JDBC Source connector and for target I have used HDFS Sink connector and kafka running in standalone mode.
- Use repository https://github.com/geeksinsights/vagrant-ansible-kafkaconnect-etl-oracle
- It will create vagrant box, create oracle database (follow instructions)
The videos which help you to understand below,
- Created table on the source side in oracle database 11g (start.sh will do)
- Which populated in hive metastore and there to hdfs partitions (start.sh will do)
- Insert/update - changes populated with ID+modified columns in my table using source jdbc connectors (video watch)
- Sink connector receives data based on the kafka topic test-jdbc-users (video watch)
- Alter table will be captured using schema registry from hive which populates structure from source to target every time. (video watch)
And You tube play list for your watching,
[embedyt] https://www.youtube.com/embed?listType=playlist&list=PLR6rN4cTV4BTxVQS-uL7NE6htS-pyLsRV&layout=gallery[/embedyt]
Hope you like it.
-Thanks
Suresh
Hello All,
This is about my weekend rumblings as I was preparing for my next presentations On Kafka + Oracle and hit many road blocks and I thought , I'd better write a post.
What I am trying to do is,
- Build a vagrant box to test Oracle and Kafka + HDFS with hive integration
- Oracle 18c, Hadoop & Hive & Confluent Kafka installed with Ansible Playbook
- Integrated Oracle -> Kafka Connect & Hive --> HDFS
- So that data/schema changes propagate to kafka topic and store in hdfs, using oracle itself as hive metastore (its causing lot of performance problems)
However, had run into many issues and able to resolve most of them successfully. Here are they. Worth for a individual posts but I will publish a full implementation video post soon.
Issue 1:- Jar Files:- Could not load jar files
ojdbc.jar is not in the configuration directories of Kafka and Hive, placed them in proper directories
[root@oracledb18c kafka-connect-jdbc]# ls -ltr
total 6140
-rw-r--r-- 1 elastic elastic 5575351 Aug 26 2016 sqlite-jdbc-3.8.11.2.jar
-rw-r--r-- 1 elastic elastic 658466 Aug 26 2016 postgresql-9.4-1206-jdbc41.jar
-rw-r--r-- 1 elastic elastic 46117 Aug 26 2016 kafka-connect-jdbc-3.0.1.jar
lrwxrwxrwx 1 root root 40 Feb 23 19:48 mysql-connector-java.jar -> /usr/share/java/mysql-connector-java.jar
lrwxrwxrwx 1 root root 26 Feb 24 13:26 ojdbc8.jar -> /usr/share/java/ojdbc8.jar
[root@oracledb18c kafka-connect-jdbc]# pwd
/opt/confluent/share/java/kafka-connect-jdbc
Issue 1:-Hive Metastore :- org.apache.hadoop.hive.metastore.hivemetaexception: Failed to get schema version.
Make sure MySQL Hive metastore , root/hive user login working properly, hive-site.xml contains proper settings. also the database metastore exists as same in the MySQL.
[vagrant@oracledb18c hive]$ cat /mnt/etc/hive/hive-site.xml.mysql
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://oracledb18c:3306/metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive@localhost</value>
</property>
Issue 2:- Kafka Connect JDBC: org.apache.kafka.connect.errors.DataException: BigDecimal has mismatching scale value for given Decimal schema
As such Oracle has number data type not numeric or the jdbc/avro format takes data with precision, a change in table definition is required, instead just number keep it as below
CREATE TABLE users (
id number(9,0) PRIMARY KEY,
name varchar2(100),
email varchar2(200),
department varchar2(200),
modified timestamp default CURRENT_TIMESTAMP NOT NULL
);
Issue 3:- Kafka Connect JDBC:- (org.apache.kafka.connect.runtime.distributed.DistributedHerder:926) java.lang.IllegalArgumentException: Number of groups must be positive.
table.whitelist and tables , not working in oracle jdbc properties , hence turned to query format. here is my properties file
[vagrant@oracledb18c hive]$ cat /mnt/etc/oracle.properties
name=test-oracle-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:oracle:thin:c##test/manager@0.0.0.0:1521/ORCLCDB
#table.whitelist=[C##TEST.USERS]
#tables=[C##TEST.USERS]
query= select * from users
mode=timestamp
incrementing.column.name=ID
timestamp.column.name=MODIFIED
topic.prefix=test_jdbc_
Issue 4:- Kafka Connect JDBC:-org.apache.kafka.connect.errors.ConnectException: Invalid type for incrementing column: BYTES
This is again due to Oracle Numeric data type conversion, when we keep mode=timestamp+incrementing it will have the above error, a Jira fix is in progress
Issue 5: Kafka Connect JDBC:- Invalid SQL type: sqlKind = UNINITIALIZED error is shown
oracle.properties file when used query do not keep quotes around.
[vagrant@oracledb18c hive]$ cat /mnt/etc/oracle.properties
name=test-oracle-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:oracle:thin:c##test/manager@0.0.0.0:1521/ORCLCDB
#table.whitelist=[C##TEST.USERS]
#tables=[C##TEST.USERS]
query=" select * from users" query=select * from users
mode=timestamp
incrementing.column.name=ID
timestamp.column.name=MODIFIED
topic.prefix=test_jdbc_
Issue 5:- Hive : Thrift Timeouts- org.apache.thrift.transport.ttransportexception: java.net.SocketTimeoutException: Read timed out (Unresolved)
Hive thrift url timing out due to below issues, I see 100% cpu for all hive thrift connections to Database.
Tasks: 181 total, 4 running, 177 sleeping, 0 stopped, 0 zombie
%Cpu(s): 51.5 us, 0.8 sy, 0.0 ni, 47.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 6808340 total, 93120 free, 2920696 used, 3794524 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1736696 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20288 oracle 20 0 2542432 87336 80080 R 100.0 1.3 584:06.49 oracleORCLCDB (LOCAL=NO)
Issue 6:- Oracle : 100% CPU , JDBC Connections - 12c Adaptive Plans
I am running 18c and it seems the optimizer_adaptive_plans is set to true by default, disabled.
Issue 7:- Oracle: 100% CPU, JDBC Connections - running for all_objects view and PGA Memory Operation waits (Unresolved)
I see lot of row cache mutex x and PGA Memory Operations,
From 12.2. the latch: row cache objects event renamed as row cache mutex x
Latches are good and light weight, however due to concurrency with JDBC connect and no stats gathers at all (a fresh database) caused this issues, collected schema, fixed, dictionary stats resolved this.
For PGA Memory Operation, seems wen running normal queries with oracle clients there's no issue , however when runs with API based JDBC connections, the memory allocation and unallocation happening.
Also the all_objects query taking long time and seems to be never come out, do not grant DBA at all for the hive metastore user. It will have to query a lot of objects since grants to dba role is vast.
More read here:-https://fritshoogland.wordpress.com/2017/03/01/oracle-12-2-wait-event-pga-memory-operation/
That's it for now.
I will publish a full implementation video soon.
-Thanks
Suresh
Hello
Today morning I opened twitter and saw lot of posts on Oracle 19c available on exadata, Thanks to Maria & others pointing me out to blogs.oracle.com. I started surfing through the links and found Oracle 19c Documentation is available and especially new features link. Here it is.
For Database Admin and Dataguard new documentation link set.
Admin New Features
Dataguard Features
and there is nicest interactive apex url for new features list for Databases 11g, 12c, 18c, 19c to scroll through. Thanks to the creators.
https://apex.oracle.com/database-features/
The features that are interesting to me are (also in https://blogs.oracle.com/database/oracle-database-19c-available-exadata ). By the way, Oracle 19c release is labelled as concentrating on stability hence expect less features.
Visit my blog dedicated page:- http://db.geeksinsight.com/19c-database/
I have created a separate page for all this here.
Started reading the documentation and you?
Thanks
Suresh
Hi
I am one of you scrolling through different metalink and master notes for latest patches for Oracle databases, and now Oracle metalink made it easy or I saw it very late :). A nice Download assistant interactive which provides all links to the relevant patches etc. Watchout this small video.
Assistant: Download Reference for Oracle Database/GI Update, Revision, PSU, SPU(CPU), Bundle Patches, Patchsets and Base Releases (Doc ID 2118136.2)
[embedyt] https://www.youtube.com/watch?v=ZaFVph1e8jI[/embedyt]
Thanks
Suresh
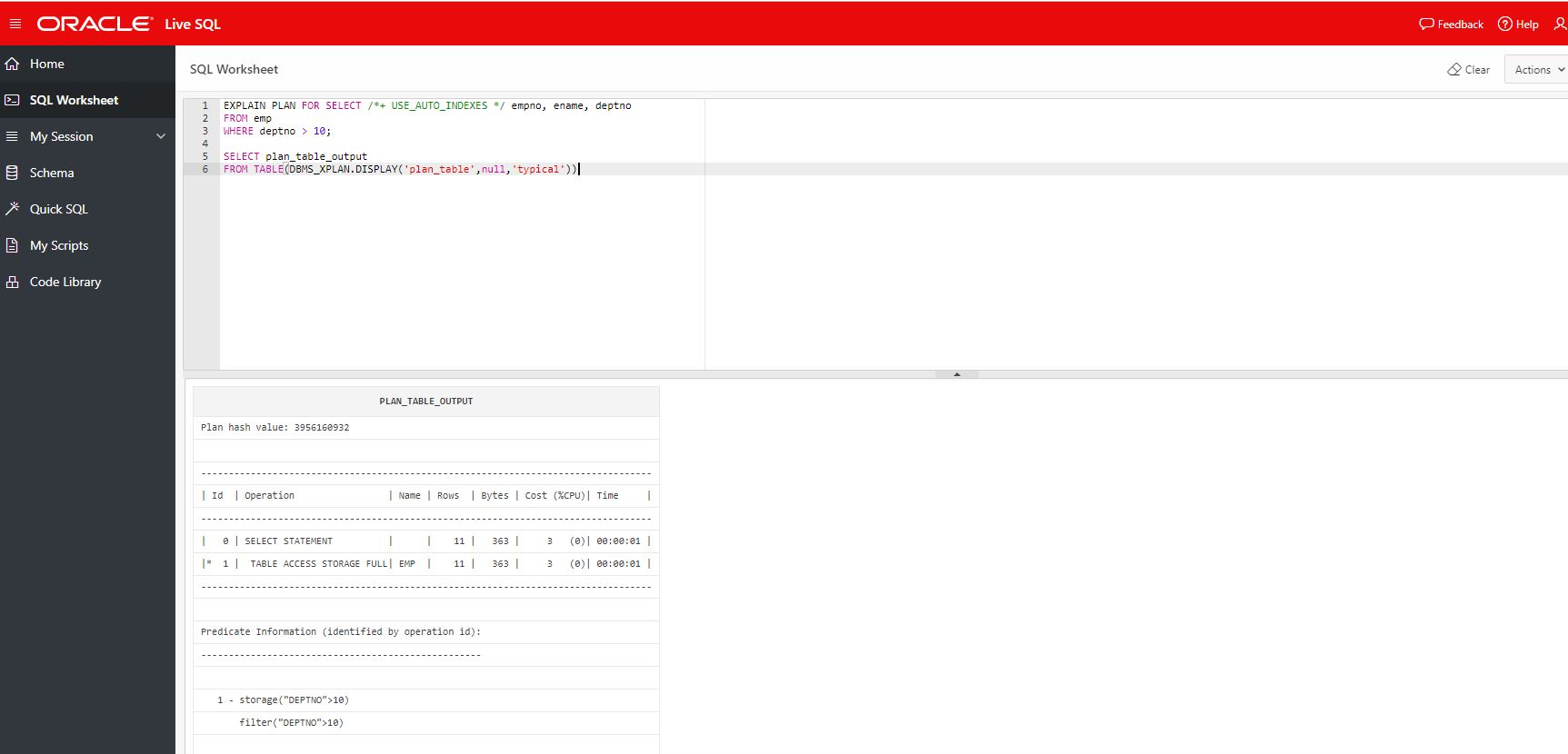
Oracle 19c was on LiveSQL and I can't wait to test out the 19c Automatic Indexing features, so I tried to create emp/dept tables and queried to use hint /*+ USE_AUTO_INDEXES */ to use automatic indexing.
To my dismay, I forgot the fact that LiveSQL is on Exadata and index scans not possible unless settings. Here's the screenshot and the execution plan showing TABLE ACCESS STORAGE FULL.
Or is there a way? I am not sure, if anyone knows, drop a comment please.
Hello
In this post, we are going to install virtualbox with vagrant and configure prometheus + grafana a open source monitoring , visualization, alerting tool. This vagrant file or playbook can be run individually, that means if you do not want to create a virtual box you can just run the playbook.
Here are the things you should know before you start
- Install Vagrant and Virtual box in your machine/laptop, even for windows, i kept local run mode for ansible so it take care.
- Download/clone the git hub repository from here
- Run the vagrant to brought up virtualbox if you need
- Run the ansible only if you want to skip vagrant
Explanation of Vagrant File:
The red lines denote
- A box prom01 is defined and centos7 image will be built, if not found locally vagrant will download from centos cloud.
- Assigned a private address some random, vagrant create a virtual interface according to it
- Forwarded the ports 9090, 3000 , so that can access grafana and prometheus URL from my localhost i.e from my OS machine
- Also assigned 1GB of memory to my newly build prom01 machine
- Provided hostname as prom01
The blue lines denote:
- Run the ansible playbook in target machine :ansibel_local if you are running vagrant from windows
- Run the ansible playbook in target machine from here :ansible if you are not running vagrant from windows.
Vagrant.configure("2") do |config|
config.vm.define "prom01" do |prom01|
prom01.vm.box = "centos/7"
prom01.vm.hostname = 'prom01'
prom01.vm.box_url = "centos/7"
prom01.vm.network :public_network, ip: "192.168.56.120"
prom01.vm.network :forwarded_port, guest: 22, host: 30122, id: "ssh"
prom01.vm.network :forwarded_port, guest: 9090, host: 9090
prom01.vm.network :forwarded_port, guest: 9093, host: 9093
prom01.vm.provider :virtualbox do |v|
v.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
v.customize ["modifyvm", :id, "--memory", 1024]
v.customize ["modifyvm", :id, "--name", "prom01"]
end
end
if Vagrant::Util::Platform.windows?
config.vm.provision :ansible_local do |ansible|
ansible.playbook = "main.yml"
end
else
config.vm.provision :ansible do |ansible|
ansible.playbook = "main.yml"
end
end
end
Some Variable stuff with Ansible Playbook
Variables: Variables are located in top of the file main.yml
node_exporter_version: 0.16.0
prometheus_version: 2.2.1
grafana_rpm: https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.1.3-1.x86_64.rpm
According to above, the node exporter which is kind of host agent will 0.16.0 version and prometheus version will be 2.2.1 and Grafana the visualisation tool will be download from aws directly.
Running vagrant
cd <repository directory>
vagrant up
Running Playbook
cd <repository directory>
ansible-playbook main.yml
Full log :-
Log Part of Vagrant
==> prom01: Checking for guest additions in VM...
prom01: No guest additions were detected on the base box for this VM! Guest
prom01: additions are required for forwarded ports, shared folders, host only
prom01: networking, and more. If SSH fails on this machine, please install
prom01: the guest additions and repackage the box to continue.
prom01:
prom01: This is not an error message; everything may continue to work properly,
prom01: in which case you may ignore this message.
==> prom01: Setting hostname...
==> prom01: Configuring and enabling network interfaces...
prom01: SSH address: 127.0.0.1:30122
prom01: SSH username: vagrant
prom01: SSH auth method: private key
==> prom01: Rsyncing folder: /cygdrive/c/Users/Sureshgandhi/Desktop/ansible-prometheus-nodeexporter-grafana/ => /vagrant
Log Part of Prometheus
prom01: Running ansible-playbook...
PLAY [prom01*] *****************************************************************
TASK [Gathering Facts] *********************************************************
ok: [prom01]
TASK [create prometheus group] *************************************************
changed: [prom01]
TASK [create prometheus user] **************************************************
changed: [prom01]
TASK [download latest version of node exporter] ********************************
changed: [prom01]
TASK [unarchive node exporter] *************************************************
changed: [prom01]
TASK [remove node exporter tarball] ********************************************
changed: [prom01]
TASK [create node exporter systemd unit file] **********************************
changed: [prom01]
TASK [set node exporter to be enabled at boot] *********************************
changed: [prom01]
TASK [download latest version of prometheus] ***********************************
changed: [prom01]
[WARNING]: Module remote_tmp /home/prometheus/.ansible/tmp did not exist and
was created with a mode of 0700, this may cause issues when running as another
user. To avoid this, create the remote_tmp dir with the correct permissions
manually
TASK [unarchive prometheus] ****************************************************
changed: [prom01]
TASK [remove node exporter tarball] ********************************************
changed: [prom01]
TASK [create prometheus systemd unit file] *************************************
changed: [prom01]
TASK [create scrape config for prometheus] *************************************
changed: [prom01]
TASK [set prometheus to be enabled at boot] ************************************
changed: [prom01]
TASK [install grafana] *********************************************************
changed: [prom01]
TASK [set grafana to be enabled at boot] ***************************************
changed: [prom01]
PLAY RECAP *********************************************************************
prom01 : ok=16 changed=15 unreachable=0 failed=0
Accessing Prometheus and Grafana from your Guest OS i.e your laptop/machine
Open your browser and type http://localhost:9090 for prometheus and http://localhost:3000 for grafana
Screenshots for the prometheus targets and grafana

Hello
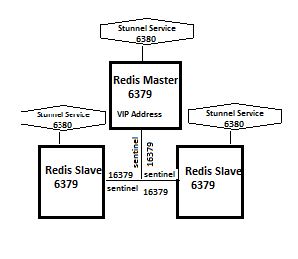
Welcome to the second part of the series DevOps for Databases, in this post we will see how to install Redis database along with HA (two slaves) , sentinel a HA solution to monitor the redis nodes and stunnel for managing SSL connections to Redis using Ansible playbook. In addition there is also a vagrant file in the repository where you can build virtualboxes with centos 7 and a playbook will run. If you do not want to run with vagrant simple run the playbook.
Here are the things you will need to understand before you start.
- Install vagrant and ansible in your machine, windows also do. Playbook will run on local mode if windows
- You can download the git repository from here.
- Look at variables in install/group_vars/redis_vars.yml for password, masternode, env etc
- By default the nodes that built in vagrant having stgredis01/02/03 you can change if you want
- If you want to use SSL and had readymade certificates copy them to install/roles/redis/files/ and mark ssl_mode: "Yes" in variable file install/group_vars/redis_vars.yml
Here is how it look like
If you want to build the machines on your laptop/machine for learning purpose. There's a file VagrantFile already in there. So run below, the following will build three boxes and provision playbook also.
cd <repositoryfolder>/
vagrant up
But if you want to run only playbook and you have machines built already
- Modify the variables in install/group_vars/redis_vars.yml
- Add the hostname in hosts file in <repositoryfolder>/hosts
Run the playbook
ansible-playbook install/redis.yml -i hosts
Log part of Vagrant
C:\Users\Sureshgandhi\Desktop\ansible-redis-sentinel-stunnel-master>vagrant up
Bringing machine 'stgredis01' up with 'virtualbox' provider...
Bringing machine 'stgredis02' up with 'virtualbox' provider...
Bringing machine 'stgredis03' up with 'virtualbox' provider...
==> stgredis01: Importing base box 'centos/7'...
Progress: 20%
==> stgredis01: Importing base box 'centos/7'...
==> stgredis01: Matching MAC address for NAT networking...
==> stgredis01: Checking if box 'centos/7' is up to date...
==> stgredis01: A newer version of the box 'centos/7' for provider 'virtualbox' is
==> stgredis01: available! You currently have version '1804.02'. The latest is version
==> stgredis01: '1812.01'. Run `vagrant box update` to update.
==> stgredis01: Setting the name of the VM: ansible-redis-sentinel-stunnel-master_stgredis01_1547554542974_39615
==> stgredis01: Clearing any previously set network interfaces...
==> stgredis01: Preparing network interfaces based on configuration...
stgredis01: Adapter 1: nat
stgredis01: Adapter 2: bridged
==> stgredis01: Forwarding ports...
stgredis01: 22 (guest) => 20122 (host) (adapter 1)
==> stgredis01: Running 'pre-boot' VM customizations...
==> stgredis01: Booting VM...
==> stgredis01: Waiting for machine to boot. This may take a few minutes...
stgredis01: SSH address: 127.0.0.1:20122
stgredis01: SSH username: vagrant
stgredis01: Inserting generated public key within guest...
stgredis01: Removing insecure key from the guest if it's present...
stgredis01: Key inserted! Disconnecting and reconnecting using new SSH key...
=> stgredis01: Machine booted and ready!
==> stgredis02: Importing base box 'centos/7'...
==> stgredis02: Matching MAC address for NAT networking...
==> stgredis02: Checking if box 'centos/7' is up to date...
==> stgredis02: A newer version of the box 'centos/7' for provider 'virtualbox' is
==> stgredis02: available! You currently have version '1804.02'. The latest is version
==> stgredis02: '1812.01'. Run `vagrant box update` to update.
==> stgredis02: Setting the name of the VM: ansible-redis-sentinel-stunnel-master_stgredis02_1547554542974_39615
==> stgredis02: Clearing any previously set network interfaces...
==> stgredis02: Preparing network interfaces based on configuration...
stgredis02: Adapter 1: nat
stgredis02: Adapter 2: bridged
==> stgredis02: Forwarding ports...
stgredis02: 22 (guest) => 20122 (host) (adapter 1)
==> stgredis02: Running 'pre-boot' VM customizations...
==> stgredis02: Booting VM...
==> stgredis02: Waiting for machine to boot. This may take a few minutes...
stgredis02: SSH address: 127.0.0.1:20122
stgredis02: SSH username: vagrant
stgredis02: Inserting generated public key within guest...
stgredis02: Removing insecure key from the guest if it's present...
stgredis02: Key inserted! Disconnecting and reconnecting using new SSH key...
=> stgredis02: Machine booted and ready!
==> stgredis03: Importing base box 'centos/7'...
==> stgredis03: Matching MAC address for NAT networking...
==> stgredis03: Checking if box 'centos/7' is up to date...
==> stgredis03: A newer version of the box 'centos/7' for provider 'virtualbox' is
==> stgredis03: available! You currently have version '1804.02'. The latest is version
==> stgredis03: '1812.01'. Run `vagrant box update` to update.
==> stgredis03: Setting the name of the VM: ansible-redis-sentinel-stunnel-master_stgredis03_1547554542974_39615
==> stgredis03: Clearing any previously set network interfaces...
==> stgredis03: Preparing network interfaces based on configuration...
stgredis03: Adapter 1: nat
stgredis03: Adapter 2: bridged
==> stgredis03: Forwarding ports...
stgredis03: 22 (guest) => 20122 (host) (adapter 1)
==> stgredis03: Running 'pre-boot' VM customizations...
==> stgredis03: Booting VM...
==> stgredis03: Waiting for machine to boot. This may take a few minutes...
stgredis03: SSH address: 127.0.0.1:20122
stgredis03: SSH username: vagrant
stgredis03: Inserting generated public key within guest...
stgredis03: Removing insecure key from the guest if it's present...
stgredis03: Key inserted! Disconnecting and reconnecting using new SSH key...
=> stgredis03: Machine booted and ready!
Log part of Playbook that is provisioned
PLAY [stgredis*] ***************************************************************
TASK [Gathering Facts] *********************************************************
ok: [stgredis01]
TASK [redis : Obtain hostname] *************************************************
changed: [stgredis01]
TASK [redis : Install dependencies] ********************************************
changed: [stgredis01]
TASK [redis : Install Yum Package] *********************************************
changed: [stgredis01]
TASK [redis : Download and install redis] **************************************
changed: [stgredis01]
TASK [redis : Create user] *****************************************************
changed: [stgredis01]
TASK [redis : Create Required Directories] *************************************
changed: [stgredis01]
TASK [redis : Disable THP support scripts added to rc.local] *******************
changed: [stgredis01]
TASK [redis : Change permissions of /etc/rc.local to make it run on boot] ******
changed: [stgredis01]
TASK [redis : Add or modify nofile soft limit for all] *************************
changed: [stgredis01]
TASK [redis : Add or modify fsize hard limit for the all. Keep or set the maximal value.] ***
changed: [stgredis01]
TASK [redis : Add or modify memlock, both soft and hard, limit for the user root with a comment.] ***
changed: [stgredis01]
TASK [redis : Add or modify hard nofile limits for wildcard *] *****************
changed: [stgredis01]
TASK [redis : Copy Redis Conf file] ********************************************
changed: [stgredis01]
TASK [redis : Copy Redis Conf file] ********************************************
changed: [stgredis01]
TASK [redis : Copy Sentinel Conf file] *****************************************
changed: [stgredis01]
TASK [redis : Copy Stunnel Conf file] ******************************************
changed: [stgredis01]
TASK [redis : Copy Redis Failover Script] **************************************
changed: [stgredis01]
TASK [redis : Change Failover Script Permissions] ******************************
TASK [redis : Create Permissions for Redis Conf Files] *************************
changed: [stgredis01]
TASK [redis : Copy Redis Init Script] ******************************************
changed: [stgredis01]
TASK [redis : Copy Sentinel Init Script] ***************************************
changed: [stgredis01]
TASK [redis : Copy Sentinel Init Script] ***************************************
changed: [stgredis01]
TASK [redis : Update redis clustername in sentinel conf] ***********************
changed: [stgredis01]
TASK [redis : Update redis masternode name in sentinel conf] *******************
changed: [stgredis01]
TASK [redis : Update redis masternode name in sentinel conf] *******************
changed: [stgredis01]
TASK [redis : Update redis VIPADDRESS in stunnel conf] *************************
ok: [stgredis01]
TASK [redis : Update redis VIPADDRES in failover script] ***********************
changed: [stgredis01]
TASK [redis : Update redis masterauth in Redis conf] ***************************
changed: [stgredis01]
TASK [redis : Update redis masterauth in Redis conf] ***************************
changed: [stgredis01]
TASK [redis : Update redis masterauth in sentinel conf] ************************
changed: [stgredis01]
TASK [redis : Update redis requirepass in Redis conf] **************************
changed: [stgredis01]
TASK [redis : Update redis datadirect in Redis conf] ***************************
changed: [stgredis01]
TASK [redis : Fix ASCII Characters issues in shell scripts] ********************
changed: [stgredis01]
TASK [redis : Update stunnel file with right keys] *****************************
changed: [stgredis01]
TASK [redis : Copy SSL Certificate to Stunnel] *********************************
skipping: [stgredis01]
TASK [redis : Copy SSL Key to Stunnel] *****************************************
skipping: [stgredis01]
TASK [redis : Update Stunnel stuff] ********************************************
skipping: [stgredis01]
TASK [redis : Copy Hosts file] ************************************************
changed: [stgredis01]
TASK [redis : Update hosts file with right environment Dev/QA/STG/PRD] *********
changed: [stgredis01]
TASK [redis : Update hosts file with right environment Dev/QA/STG/PRD] *********
changed: [stgredis01]
TASK [redis : Update hosts file with right subnet] *****************************
ok: [stgredis01]
TASK [redis : Add Line for slaveof configuration] ******************************
ok : [stgredis01]
TASK [redis : Start redis Service] *********************************************
changed: [stgredis01]
TASK [redis : Start sentinel service] ******************************************
changed: [stgredis01]
TASK [redis : Start Stunnel service] *******************************************
skipping: [stgredis01]
PLAY RECAP *********************************************************************
stgredis01 : ok=41 changed=38 unreachable=0 failed=0
Redis Status once Boxes built and Provisioned
Note: There's lot of warnings and optimizations need for Playbook, feel free to modify the repository code and commit. When I find some time will do accordingly.
Happy Learning
-Suresh
Hello All,
In this post, I will show you how to build a virtualbox using vagrant and install postgres with primary and standby configurations with hot standby mode. This all will be done in less than 1 hr and postgres HA is available for your learning purpose. You will be learning about vagrant and ansible and how to simply convert your scripts and commands to your ansible way of doing.
Here are few things you need to know before you proceed.
- If you are on windows, install Virtualbox and Vagrant windows variants
- Install git in your windows or just download the zip file from my git repository
- Unzip the repository
- You will see
- VagrantFile -
- File that builds two machines prodpsql01 and prodpsql02 for postgres with 1024MB each
- Provision the Ansible playbook postgres.yml
- install/postgres.yml
- Run's a role postgres-master which creates a primary database on prodpsql01
- Run's a role postgres-slave which creates a standby database on prodpsql02
- group_vars/postgres_vars.yml
- Variables for your postgres database ex: passwords, data directories etc.
Installation
Open your command prompt and navigate to the directory where you have download and extracted the repository
C:\Users\Sureshgandhi\Desktop\vagrant+ansible+postgres+ha
simply run
vagrant up
and you will see the centos image downloading, creating virtualbox, running ansible, Sample log as below. For first time it take time to download image.
Part of log that provision first node, prodpsql01
C:\Users\Sureshgandhi\Desktop\ansible-postgres-master>vagrant up
Bringing machine 'prodpsql01' up with 'virtualbox' provider...
Bringing machine 'prodpsql02' up with 'virtualbox' provider...
==> prodpsql01: Importing base box 'centos/7'...
==> prodpsql01: Matching MAC address for NAT networking...
==> prodpsql01: Checking if box 'centos/7' is up to date...
==> prodpsql01: A newer version of the box 'centos/7' for provider 'virtualbox' is
==> prodpsql01: available! You currently have version '1804.02'. The latest is version
==> prodpsql01: '1811.02'. Run `vagrant box update` to update.
==> prodpsql01: Setting the name of the VM: ansible-postgres-master_prodpsql01_1547405089078_26371
==> prodpsql01: Clearing any previously set network interfaces...
==> prodpsql01: Preparing network interfaces based on configuration...
prodpsql01: Adapter 1: nat
prodpsql01: Adapter 2: bridged
==> prodpsql01: Forwarding ports...
prodpsql01: 22 (guest) => 10122 (host) (adapter 1)
==> prodpsql01: Running 'pre-boot' VM customizations...
==> prodpsql01: Booting VM...
==> prodpsql01: Waiting for machine to boot. This may take a few minutes...
prodpsql01: SSH address: 127.0.0.1:10122
prodpsql01: SSH username: vagrant
prodpsql01: SSH auth method: private key
prodpsql01:
prodpsql01: Vagrant insecure key detected. Vagrant will automatically replace
prodpsql01: this with a newly generated keypair for better security.
prodpsql01:
prodpsql01: Inserting generated public key within guest...
prodpsql01: Removing insecure key from the guest if it's present...
prodpsql01: Key inserted! Disconnecting and reconnecting using new SSH key...
==> prodpsql01: Machine booted and ready!
[prodpsql01] No installation found.
Loaded plugins: fastestmirror
Determining fastest mirrors
* base: centos.excellmedia.net
* extras: centos.excellmedia.net
* updates: centos.excellmedia.net
Part of the log that Install postgres in first node
==> prodpsql01: Running provisioner: ansible_local...
prodpsql01: Installing Ansible...
Vagrant has automatically selected the compatibility mode '2.0'
according to the Ansible version installed (2.7.5).
Alternatively, the compatibility mode can be specified in your Vagrantfile:
https://www.vagrantup.com/docs/provisioning/ansible_common.html#compatibility_mode
prodpsql01: Running ansible-playbook...
PLAY [prodpsql01] **************************************************************
TASK [Gathering Facts] *********************************************************
ok: [prodpsql01]
TASK [postgres-master : Obtain hostname] ***************************************
changed: [prodpsql01]
TASK [postgres-master : Install Postgres and InitDB] ***************************
changed: [prodpsql01]
[WARNING]: Consider using the yum module rather than running yum. If you need
to use command because yum is insufficient you can add warn=False to this
command task or set command_warnings=False in ansible.cfg to get rid of this
message.
TASK [postgres-master : Create Repmgr directories] *****************************
changed: [prodpsql01]
[WARNING]: Consider using the file module with state=directory rather than
running mkdir. If you need to use command because file is insufficient you can
add warn=False to this command task or set command_warnings=False in
ansible.cfg to get rid of this message.
TASK [postgres-master : Copy Postgres Conf file] *******************************
changed: [prodpsql01]
TASK [postgres-master : Copy repmgr conf file] *********************************
changed: [prodpsql01]
TASK [postgres-master : Modify postgresql.conf] ********************************
ok: [prodpsql01] => (item={u'path': u'/data/postgresql.conf', u'regexp1': u'masternode', u'replace': u'prodpsql01.localdomain'})
changed: [prodpsql01] => (item={u'path': u'/data/postgresql.conf', u'regexp1': u'dataDir', u'replace': u'/data/'})
TASK [postgres-master : Replace in repmgr.conf] ********************************
changed: [prodpsql01] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'masternode', u'replace': u'prodpsql01.localdomain'})
changed: [prodpsql01] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'env', u'replace': u'prod'})
changed: [prodpsql01] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'dataDir', u'replace': u'/data/'})
TASK [postgres-master : Replace in service file] *******************************
changed: [prodpsql01] => (item={u'path': u'/usr/lib/systemd/system/postgresql-9.6.service', u'regexp1': u'/var/lib/pgsql/9.6/data/', u'replace': u'/data/'})
TASK [postgres-master : Set some stuff] ****************************************
changed: [prodpsql01]
TASK [postgres-master : add .pgpass file] **************************************
changed: [prodpsql01]
TASK [postgres-master : Start Postgres] ****************************************
changed: [prodpsql01]
[WARNING]: Consider using the service module rather than running service. If
you need to use command because service is insufficient you can add warn=False
to this command task or set command_warnings=False in ansible.cfg to get rid of
this message.
TASK [postgres-master : Create Admin/Repmgr logins] ****************************
changed: [prodpsql01]
[WARNING]: Consider using 'become', 'become_method', and 'become_user' rather
than running sudo
TASK [postgres-master : Copy Postgres pg_hba file] *****************************
changed: [prodpsql01]
TASK [postgres-master : Set hostnames in the /etc/hosts] ***********************
changed: [prodpsql01]
TASK [postgres-master : stop and start postgres] *******************************
changed: [prodpsql01]
TASK [postgres-master : Register as master] ************************************
changed: [prodpsql01]
[WARNING]: Consider using 'become', 'become_method', and 'become_user' rather
than running su
PLAY [prodpsql02] **************************************************************
skipping: no hosts matched
PLAY RECAP *********************************************************************
prodpsql01 : ok=17 changed=16 unreachable=0 failed=0
Part of the log that provision second node for standby i.e prodpsql02
==> prodpsql02: Checking for guest additions in VM...
prodpsql02: No guest additions were detected on the base box for this VM! Guest
prodpsql02: additions are required for forwarded ports, shared folders, host only
prodpsql02: networking, and more. If SSH fails on this machine, please install
prodpsql02: the guest additions and repackage the box to continue.
prodpsql02:
prodpsql02: This is not an error message; everything may continue to work properly,
prodpsql02: in which case you may ignore this message.
==> prodpsql02: Setting hostname...
==> prodpsql02: Configuring and enabling network interfaces...
prodpsql02: SSH address: 127.0.0.1:10123
prodpsql02: SSH username: vagrant
prodpsql02: SSH auth method: private key
==> prodpsql02: Rsyncing folder: /cygdrive/c/Users/Sureshgandhi/Desktop/ansible-postgres-master/ => /vagrant
Part of the log that provision ansible playbook to create postgres standby on second node i.e prodpsql02
PLAY [prodpsql02] **************************************************************
TASK [Gathering Facts] *********************************************************
ok: [prodpsql02]
TASK [postgres-slave : Obtain hostname] ****************************************
changed: [prodpsql02]
TASK [postgres-slave : Install Postgres and InitDB] ****************************
changed: [prodpsql02]
[WARNING]: Consider using the yum module rather than running yum. If you need
to use command because yum is insufficient you can add warn=False to this
command task or set command_warnings=False in ansible.cfg to get rid of this
message.
TASK [postgres-slave : add .pgpass file] ***************************************
changed: [prodpsql02]
TASK [postgres-slave : Create Repmgr directories] ******************************
changed: [prodpsql02]
[WARNING]: Consider using the file module with state=directory rather than
running mkdir. If you need to use command because file is insufficient you can
add warn=False to this command task or set command_warnings=False in
ansible.cfg to get rid of this message.
TASK [postgres-slave : Copy repmgr conf file] **********************************
changed: [prodpsql02]
TASK [postgres-slave : Replace in repmgr.conf] *********************************
changed: [prodpsql02] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'slavenode', u'replace': u'prodpsql02.localdomain'})
changed: [prodpsql02] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'env', u'replace': u'prod'})
changed: [prodpsql02] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'dataDir', u'replace': u'/data/'})
changed: [prodpsql02] => (item={u'path': u'/var/lib/pgsql/repmgr/repmgr.conf', u'regexp1': u'node_id=1', u'replace': u'node_id=2'})
TASK [postgres-slave : Replace in service file] ********************************
changed: [prodpsql02] => (item={u'path': u'/usr/lib/systemd/system/postgresql-9.6.service', u'regexp1': u'/var/lib/pgsql/9.6/data/', u'replace': u'/data/'})
TASK [postgres-slave : Set some stuff] *****************************************
changed: [prodpsql02]
TASK [postgres-slave : Set hostnames in the /etc/hosts] ************************
changed: [prodpsql02]
TASK [postgres-slave : Clone the standby from primary and register it] *********
changed: [prodpsql02]
[WARNING]: Consider using 'become', 'become_method', and 'become_user' rather
than running su
TASK [postgres-slave : Clone the standby from primary and register it] *********
changed: [prodpsql02]
PLAY RECAP *********************************************************************
prodpsql02 : ok=12 changed=11 unreachable=0 failed=0
That's it, Postgres with Primary and Standby is ready, let's jump on to the box and verify.
run in the same directory
vagrant ssh prodpsql01
run the repmgr command to check the cluster status
sudo su -
su - postgres -c "repmgr -f /var/lib/pgsql/repmgr/repmgr.conf cluster show"
and here is the snippet

Hello All
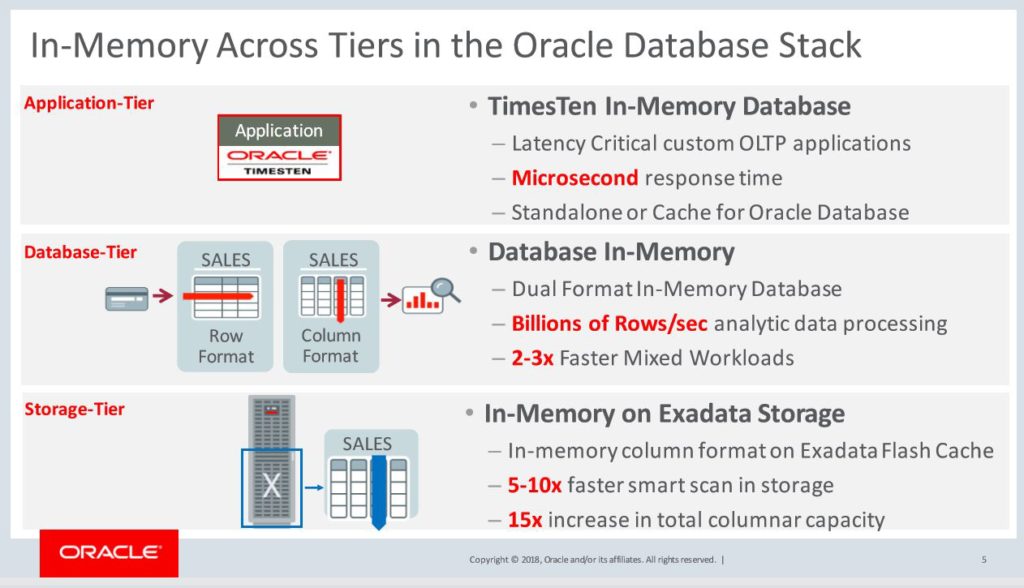
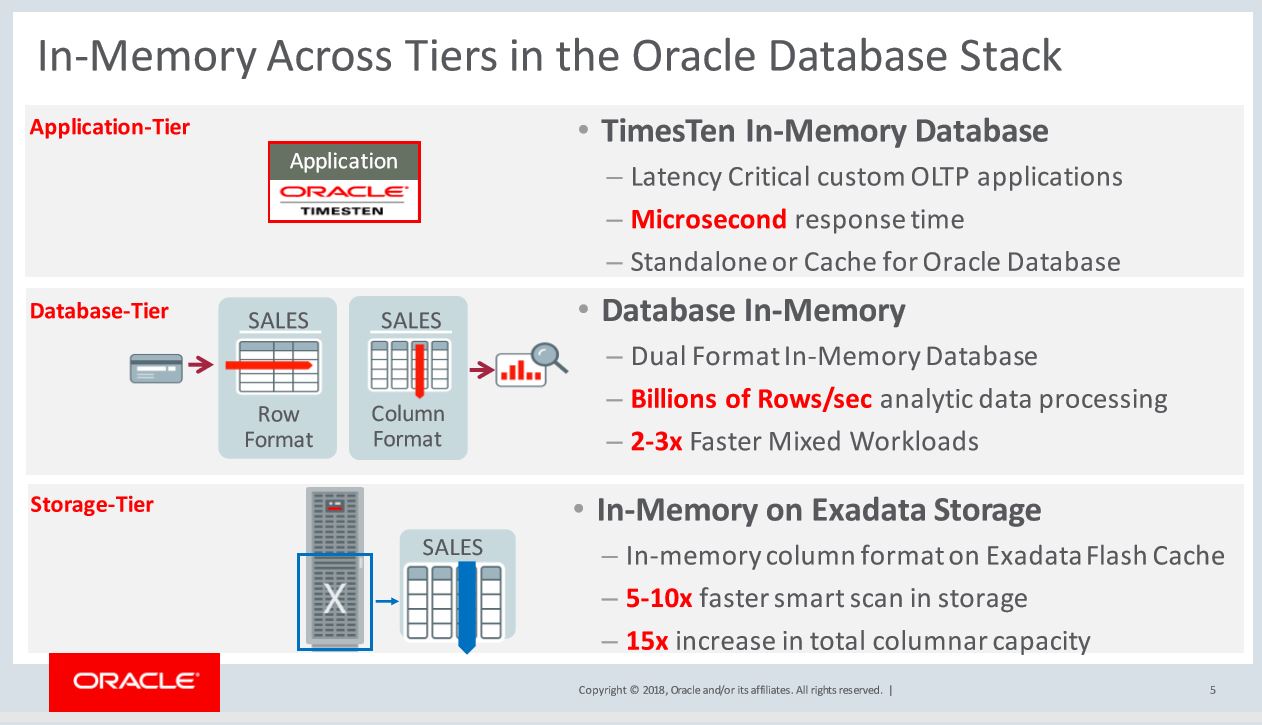
One of the #OOW18 presentations slides on In Memory by @TirthankarLahari @dbinmemory and Oracle In Memory features across tiers explained. And listen more from him @sangam18 , #sangam18, @aioug at Bengalure 7th and 8th.
Thanks
Suresh
In constant pursuit of human race behind technology with all due respect of it this post dedicated to all those of like mine.
Often I (in fact everyone of reading this) am been asked a question , what is future of DBA with cloud, autonomous etc.
Well that's not for only DBA's its every where, BA/BI roles has been renamed as Data Scientists and Server Admins already adopted Infrastructure as Code with advent of cloud etc. And some of our folks already been working in BigData or NoSQL classified them as Data Engineers (Build/Run/Maintain clusters). So its time for rest of folks to look at that aspect. We may no more been called DBA's ( do not know even what we will be called in next 5-10 years). I remember Arup Nanda blogged long time back when Exadata is on its way and he written DBA's as DMA's. So lets wait someone let call us something 🙂
Back to question, "Future of DBA", surely its not any more a single technology it should be multifold, I tried to put it in on my own way below as separate quadrant and they are equally important, so that I track my self am I covering what Industry has been. We need to learn (constant pursuit of human race behind technology) a lot, indeed its not a mid career switch infact its beginning. Those who already started that's good if not its time to start.
Of course, the list below are latest buzz in industry now, when we actually learn and try to apply they may fade away (or not). But let's start one in each one this quadrants. You don't need to mastered but you will need to be enough knowledgeable to run the things. (as IT Operations has only thing to do is Run the Business)
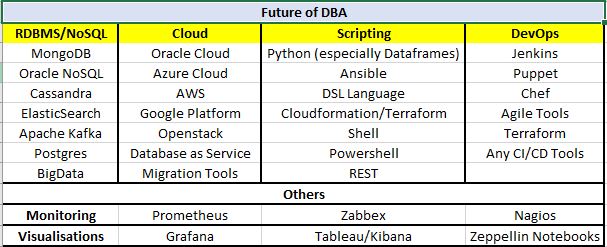
I have not added the Virtualisation/Hypervisor in the list, since they are different from what above. So ideally this is it
Containerization and Virtualization play vital role in building microservices, so it will be helpful if you start learning how Docker Container works and tools like kubernetes etc.
Hope this helps
Happy to take questions on this 🙂
Thanks
Suresh
|
Follow Me!!!