All information is offered in good faith and in the hope that it may be of use for educational purpose and for Database community purpose, but is not guaranteed to be correct, up to date or suitable for any particular purpose. db.geeksinsight.com accepts no liability in respect of this information or its use.
This site is independent of and does not represent Oracle Corporation in any way. Oracle does not officially sponsor, approve, or endorse this site or its content and if notify any such I am happy to remove.
Product and company names mentioned in this website may be the trademarks of their respective owners and published here for informational purpose only.
This is my personal blog. The views expressed on these pages are mine and learnt from other blogs and bloggers and to enhance and support the DBA community and this web blog does not represent the thoughts, intentions, plans or strategies of my current employer nor the Oracle and its affiliates or any other companies. And this website does not offer or take profit for providing these content and this is purely non-profit and for educational purpose only.
If you see any issues with Content and copy write issues, I am happy to remove if you notify me.
Contact Geek DBA Team, via geeksinsights@gmail.com
Learning AI at this level is like learning how to search effectively on Google—knowing how to ask the right questions. It’s about writing good prompts for GenAI tools and extracting meaningful information from them. At this stage, we are essentially AI users, much like internet users. Prompt engineering falls into this category, but the real question is: do you actually want to go deep into this, or just practice and improve over time?
2. Understanding How AI Is Built
This level focuses on the fundamentals:
How AI and LLMs are architected
What models, weights, and training really mean
How these systems work under the hood
This path is meant for those who want to become AI researchers or AI developers, or who plan to work directly on building AI/LLM models themselves.
3. Applying AI as an IT Engineer
This is about leveraging AI to build real-world solutions as an IT professional. Examples include using tools and platforms such as:
QGenie
Copilot
Cline
n8n
A2A, MCP, AI agents, and similar frameworks
Claude Code
Here, the focus is not on building models from scratch, but on using AI effectively to solve business and engineering problems.
Some interesting Courses List (highlighted important ones for your convenience)
1. Using AI Effectively (Prompting / AI as a User)
Focus: writing good prompts, interacting with GenAI tools, productivity use cases.
Vector features represent data as high-dimensional numerical arrays, enabling AI models to understand complex relationships and patterns. Vector databases are crucial in the AI era for storing and retrieving these embeddings efficiently, powering applications like semantic search, recommendation systems, and generative AI.
Here are the popular databases and its vectors features. Hope this is useful
Oracle Database 23ai introduces robust vector support through: SQL Functions: VECTOR_CHUNKS for text chunking and VECTOR_EMBEDDING for generating embeddings directly in SQL. PL/SQL Packages: DBMS_VECTOR and DBMS_VECTOR_CHAIN for embedding generation, text processing, and similarity search. These can be scheduled as end-to-end pipelines. Embedding Models: Supports ONNX format models and third-party REST APIs for embedding generation
BEGIN DBMS_VECTOR_CHAIN.CREATE_MODEL( model_name => 'my_embedding_model', model_path => '/path/to/model.onnx' ); END;
SELECT VECTOR_EMBEDDING('my_embedding_model', 'sample text') FROM DUAL;
Similarity Search: SELECT * FROM my_table WHERE VECTOR_DISTANCE(my_vector_column, VECTOR_EMBEDDING('model', 'query text')) < 0.5;
MySQL
✅ Native support
MySQL has added vector data types in recent versions, allowing integrated semantic search
Free
MySQL 9.0 introduces the VECTOR(N) data type: Structure: Stores up to 16,383 single-precision floats. Functions: Includes STRING_TO_VECTOR(), VECTOR_TO_STRING(), VECTOR_DIM(), and DISTANCE() for similarity calculations. Limitations: Cannot be used as keys, in aggregate functions, or with most numeric and JSON functions. Cloud SQL Extension: Google Cloud SQL for MySQL supports vector embeddings via VARBINARY columns and ANN/KNN indexing with types like TREE_SQ, TREE_AH, and BRUTE_FORCE
CREATE TABLE vectors ( id INT PRIMARY KEY, embedding VECTOR(768) );
INSERT INTO vectors VALUES (1, STRING_TO_VECTOR('[0.1, 0.2, ..., 0.768]'));
Similarity Search: SELECT id FROM vectors WHERE DISTANCE(embedding, STRING_TO_VECTOR('[0.1, 0.2, ..., 0.768]'), 'COSINE') < 0.2;
MSSQL
🚧 Limited/Custom
No native vector support yet; can be emulated via extensions or external libraries.
Licensed
Status: No native vector data type. Workaround: Embeddings can be stored as binary or JSON and similarity search implemented via external libraries or integration with vector databases like FAISS or Milvus.
Workaround: Store embeddings as VARBINARY(MAX) or JSON. Use CLR or external Python/FAISS for similarity search.
PostgreSQL
✅ Via Extensions
Supports vector search using extensions like pgvector; widely adopted for AI workloads.
Free
Extension: pgvector is the primary method. Capabilities: Supports vector storage, similarity search (cosine, L2, inner product), and indexing via HNSW or IVF. Integration: Widely used in AI pipelines and supports ONNX models via external tools.
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE items ( id SERIAL PRIMARY KEY, embedding VECTOR(768) );
SELECT * FROM items ORDER BY embedding <-> '[0.1, 0.2, ..., 0.768]' LIMIT 5;
Cassandra
✅ Through Astra Vector
Astra DB (based on Cassandra) supports vector search with DiskANN indexing
Licensed
Astra DB: DataStax’s managed Cassandra supports vector search using DiskANN indexing. Implementation: Embeddings stored as arrays; similarity search via ANN algorithms.
Store vectors as arrays in a column. Use Astra’s vector search API: { "vector": [0.1, 0.2, ..., 0.768], "top_k": 5 }
Elasticsearch
✅ Native support
Offers vector search via kNN and ANN indexing; widely used for hybrid search
Free
Native Support: Uses dense_vector and knn_vector fields. Indexing: Supports HNSW for ANN search. Querying: knn search queries with cosine, dot product, or Euclidean distance.
MongoDB Atlas includes full-featured vector search for generative AI and semantic applications
Free
Atlas Vector Search: Native support in MongoDB Atlas. Indexing: Uses HNSW for fast ANN search. Integration: Embeddings stored as arrays; supports OpenAI and HuggingFace models
Redis supports vector search through modules like Redisearch and Redis Vector.
Free
Modules: Redisearch and Redis Vector. Storage: Embeddings stored as vectors in Redis keys. Search: Supports cosine, dot product, and Euclidean distance.
Store vectors and hashes as Json Create Index FT.CREATE idx ON HASH PREFIX 1 doc: SCHEMA embedding VECTOR FLAT 6 DIM 768 DISTANCE_METRIC COSINE Query: FT.SEARCH idx "*=>[KNN 5 @embedding $vec]" PARAMS 2 vec "[0.1, 0.2, ..., 0.768]" DIALECT 2
Snowflake
✅ Native support
Snowflake supports vector embeddings and retrieval-augmented generation (RAG) use cases
Licensed
Native Support: Embedding storage and similarity search. Functions: Includes vector distance functions and supports RAG pipelines. Integration: Works with external models and Snowpark for ML.
Store vectors as arrays. Use UDFs for similarity: CREATE FUNCTION cosine_similarity(vec1 ARRAY, vec2 ARRAY) RETURNS FLOAT LANGUAGE SQL AS '...'; Query: SELECT * FROM embeddings WHERE cosine_similarity(embedding, ARRAY_CONSTRUCT(0.1, 0.2, ..., 0.768)) > 0.8;
Redshift
🚧 Limited
No native vector support; can be integrated with external vector stores or used with UDFs.
Licensed
Status: No native vector support. Workaround: Embeddings stored as arrays or JSON; similarity search via UDFs or integration with external vector stores.
Store vectors as arrays or JSON. Use UDFs or external services for similarity.
Vertica
🚧 Limited
Vertica does not natively support vector data types or similarity search functions like cosine or inner product out of the box. However, it offers workarounds and integrations that allow you to simulate vector database behavior:
Licensed
You can store embeddings using the ARRAY data type. You can implement distance metrics using User-Defined Functions (UDFs) or User-Defined Extensions (UDXs). Vertica integrates with external AI frameworks and supports Python-based ML workflows via VerticaPy.
CREATE TABLE embeddings ( id INT, vector ARRAY[FLOAT] ); from verticapy.learn import RandomForestRegressor model = RandomForestRegressor().fit("training_table") predictions = model.predict("test_table") SELECT sentiment_udx(text_column) FROM reviews;
Neo4J
✅ Native support
starting with Neo4j 5.11 (beta) and 5.13 (GA), it introduced vector indexes that enable similarity search and AI-driven analytics. These indexes allow you to store and query vector embeddings directly within graph nodes or relationships
Licensed
starting with Neo4j 5.11 (beta) and 5.13 (GA), it introduced vector indexes that enable similarity search and AI-driven analytics. These indexes allow you to store and query vector embeddings directly within graph nodes or relationships Vector Indexes: Store embeddings as LIST<FLOAT> properties. Similarity Search: Supports cosine and Euclidean distance. Powered by: Apache Lucene indexing engine.
CREATE (m:Movie {title: "The Godfather", embedding: [0.0059, -0.0381, ..., 0.0188]});
CREATE VECTOR INDEX movie_embedding_index FOR (m:Movie) ON (m.embedding) OPTIONS {indexConfig: {similarityFunction: 'cosine'}};
Oracle 23ai is made generally available and it has got 300+ new features including AI related.
Here is the list of new features from Oracle Blog (Dominic Giles) and I will write detailed posts on some of these features which may useful to DBAs and Developers.
From various blogs and posts, here is the summary of New features in upcoming release of Oracle database 23c.
OLTP and Core DB:
Accelerate SecureFiles LOB Write Performance Automatic SecureFiles Shrink Automatic Transaction Abort Escrow Column Concurrency Control Fast Ingest (Memoptimize for Write) Enhancements Increased Column Limit to 4k Managing Flashback Database Logs Outside the Fast Recovery Area Remove One-Touch Restrictions after Parallel DML Annotations – Define Metadata for Database Objects SELECT Without the FROM Clause Usage of Column Alias in GROUP BY and HAVING Table Value Constructor – Group Multiple Rows of Data in a Single DML or SELECT statement Better Error Messages to Explain why a Statement Failed to Execute New Developer Role: dbms_developer_admin.grant_privs(‘JULIAN’); Schema Level Privileges RUR’s are transitioning to MRPs (available on Linux x86-64)
Application Development:
Aggregation over INTERVAL Data Types Asynchronous Programming Blockchain Table Enhancements DEFAULT ON NULL for UPDATE Statements Direct Joins for UPDATE and DELETE Statements GROUP BY Column Alias or Position Introduction to Javascript Modules and MLE Environments MLE – Module Calls New Database Role for Application Developers OJVM Web Services Callout Enhancement OJVM Allow HTTP and TCP Access While Disabling Other OS Calls Oracle Text Indexes with Automatic Maintenance Sagas for Microservices SQL Domains SQL Support for Boolean Datatype SQL UPDATE RETURN Clause Enhancements Table Value Constructor Transparent Application Continuity Transportable Binary XML Ubiquitous Search With DBMS_SEARCH Packages Unicode IVS (Ideographic Variation Sequence) Support
Compression:
Improve Performance and Disk Utilization for Hybrid Columnar Compression Index-Organized Tables (IOTs) Advanced Low Compression
Data Guard:
Per-PDB Data Guard Integration Enhancements
Event Processing:
Advanced Queuing and Transactional Event Queues Enhancements OKafka (Oracle’s Kafka implementation) Prometheus/Grafana Observability for Oracle Database
In-Memory:
Automatic In-Memory enhancements for improving column store performance
Java:
JDBC Enhancements to Transparent Application Continuity JDBC Support for Native BOOLEAN Datatype JDBC Support for OAuth2.0 for DB Authentication and Azure AD Integration JDBC Support for Radius Enhancements (Challenge Response Mode a.k.a. Two Factor Authentication) JDBC Support for Self-Driven Diagnosability JDBC-Thin support for longer passwords UCP Asynchronous Extension
JSON:
JSON-Relational Duality View JSON SCHEMA
RAC:
Local Rolling Patching Oracle RAC on Kubernetes Sequence Optimizations in Oracle RAC Simplified Database Deployment Single-Server Rolling Patching Smart Connection Rebalance
Security:
Ability to Audit Object Actions at the Column Level for Tables and Views Enhancements to RADIUS Configuration Increased Oracle Database Password Length: 1024 Byte Password Schema Privileges to Simplify Access Control TLS 1.3
Sharding:
JDBC Support for Split Partition Set and Directory based Sharding New Directory-Based Sharding Method RAFT Replication UCP Support for XA Transactions with Oracle Database Sharding
Spatial and Graph:
Native Representation of Graphs in Oracle Database Spatial: 3D Models and Analytics Spatial: Spatial Studio UI Support for Point Cloud Features Support for the ISO/IEC SQL Property Graph Queries (SQL/PGQ) Standard Use JSON Collections as a Graph Data Source
Source: Lucas Jellema, renenyffenegger, threadreaderapp, phsalvisberg, juliandontcheff
Here is the script and snippet of Average Active Sessions plotted by Hour in Oracle database. This is similar to Oracle Log switch history.
This helps DBA to understand the hourly metric of AAS and determine any spikes of the active sessions for the problematic period or gather some particular trend of AAS.
My first check would be this when some one say during particular time the database performance was slow etc etc. AAS helps us to determine how many active sessions were during that period which threshold to CPU count parameter in the database. If the value is less that CPU count means the database still can process if not database is experiencing load and sessions has to wait for CPU calls.
The query takes max value of the metric Average Active Session from DBA_HIST_SYSMETRIC_SUMMARY for last 7 days and plot by hourly using decode.
set linesize 300 col day for a11 col 00 format 999999 col 01 format 999999 col 02 format 999999 col 03 format 999999 col 04 format 999999 col 05 format 999999 col 06 format 999999 col 07 format 999999 col 08 format 999999 col 09 format 999999 col 10 format 999999 col 11 format 999999 col 12 format 999999 col 13 format 999999 col 14 format 999999 col 15 format 999999 col 16 format 999999 col 17 format 999999 col 18 format 999999 col 19 format 999999 col 20 format 999999 col 21 format 999999 col 22 format 999999 col 23 format 999999 select to_char(begin_time,'DD-MON-YY') Day, round(max(decode(to_char(begin_time,'HH24'),'00',maxval,NULL)),2) "00", round(max(decode(to_char(begin_time,'HH24'),'01',maxval,NULL)),2) "01", round(max(decode(to_char(begin_time,'HH24'),'02',maxval,NULL)),2) "02", round(max(decode(to_char(begin_time,'HH24'),'03',maxval,NULL)),2) "03", round(max(decode(to_char(begin_time,'HH24'),'04',maxval,NULL)),2) "04", round(max(decode(to_char(begin_time,'HH24'),'05',maxval,NULL)),2) "05", round(max(decode(to_char(begin_time,'HH24'),'06',maxval,NULL)),2) "06", round(max(decode(to_char(begin_time,'HH24'),'07',maxval,NULL)),2) "07", round(max(decode(to_char(begin_time,'HH24'),'08',maxval,NULL)),2) "08", round(max(decode(to_char(begin_time,'HH24'),'09',maxval,NULL)),2) "09", round(max(decode(to_char(begin_time,'HH24'),'10',maxval,NULL)),2) "10", round(max(decode(to_char(begin_time,'HH24'),'11',maxval,NULL)),2) "11", round(max(decode(to_char(begin_time,'HH24'),'12',maxval,NULL)),2) "12", round(max(decode(to_char(begin_time,'HH24'),'13',maxval,NULL)),2) "13", round(max(decode(to_char(begin_time,'HH24'),'14',maxval,NULL)),2) "14", round(max(decode(to_char(begin_time,'HH24'),'15',maxval,NULL)),2) "15", round(max(decode(to_char(begin_time,'HH24'),'16',maxval,NULL)),2) "16", round(max(decode(to_char(begin_time,'HH24'),'17',maxval,NULL)),2) "17", round(max(decode(to_char(begin_time,'HH24'),'18',maxval,NULL)),2) "18", round(max(decode(to_char(begin_time,'HH24'),'19',maxval,NULL)),2) "19", round(max(decode(to_char(begin_time,'HH24'),'20',maxval,NULL)),2) "20", round(max(decode(to_char(begin_time,'HH24'),'21',maxval,NULL)),2) "21", round(max(decode(to_char(begin_time,'HH24'),'21',maxval,NULL)),2) "22", round(max(decode(to_char(begin_time,'HH24'),'21',maxval,NULL)),2) "23" from dba_hist_sysmetric_SUMMARY A where BEGIN_TIME > sysdate - 15 and A.METRIC_NAME in('Average Active Sessions') group by to_char(begin_time,'DD-MON-YY') order by to_char(begin_time,'DD-MON-YY') ;
As you see the sessions were spike during 21:00PM to 04:00AM during 14th and 20th dates.
Looks like some more exciting features / enhancements is going to appear in Oracle 23c as per DAOUG presentations. Hope lot more will be announced in OCW22.
From Productivity Stand point view
4K Columns
SQL Domains
JSON Schema
Developer Role
Schema-Level Privileges
JS Stored Procedures
Single Server rolling maintenance
Native property graphs
From Simplicity stand
Rest API's for auto upgrade
Oracle RAC on K8s
Easier Time Zone data upgrade
1024 Bytes Passwords
PLSQL to SQL Transfer & vice versa
OAuth 2.0 Integration
Better Return clause
Oracle <--> Kafka Integration ( I written this sometime back)
Better Ora Error Messages
For Easier Cloud Migration
Auto upgrade with keystore access
Auto upgrade unplug/plug
ZDM Support for Standby DB
ZDM support for DG Broker
Cloud pre migration assessment tool
Source: technology.amis.nl, DAOUG - presentation by Gerald Venzl
This post is intended to give you an understanding of upcoming series of Timeseries analysis and how it can be useful to predict issues that may arise in future or predict growth etc.
Think of this, Many of the SRE's or admins work today mostly by doing reactive fixes (some may not) as they get alerted for something and they will fix it.
How about predicting those occurrences and adjust them proactive. isn't your oncall or day job is easy?
In my point of view (other may differ), most of our incidents, alerts that we receive are timestamped with there possible threshold breach value of that metric and they are exactly time series data as like other data sets like share price, weather, population. etc. And if you want to learn some machine learning or AI/ML models why cant we play with our own data and do a meaningful research or POC for productive result instead downloading datasets of irrelevant and do practices on them.
Here is it, as we figured out we have the time series data what all we can do.
Typically these are the alerts that we get as SRE's or Admins,
Service Down/up
Filesystem Alert
Storage Growth
High number of connections
High Load Averages
I/O Latencies
DB Response Time
Is it not? So what can we do with them.
Per say, If we have data of that particular server up/down for last 12 months or 30 days, we can predict and tell what is the probability that this server can go down or particular can down in next 30 days.
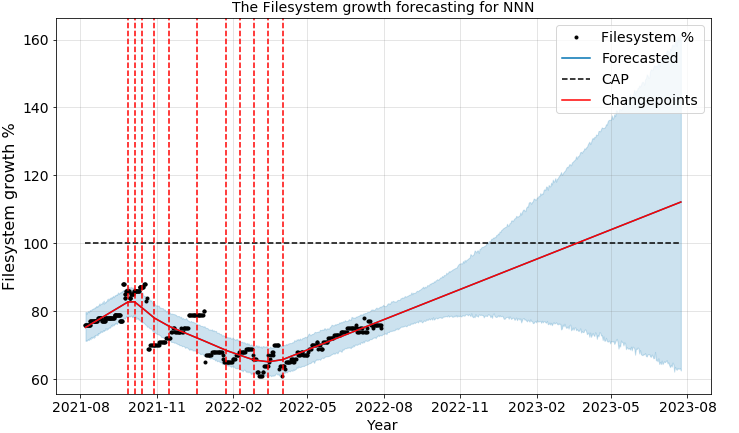
Or, if we have data of filesystem alerts of last 6 months, we can foresee when the filesystem reach 100 percent based on usage in past.
And, we can predict when is the database response time is going to be bad based on previous data points by gathering SQL response metric from Oracle database.
All we can do is to do Time series analysis and do prediction using Linear Regression models using python statsmodels, sclearnkit, fbprophet etc.
Hope you got the gist of what I am going to do in next few posts.
Intro - Time Series analysis Fundamentals
Time Series analysis using python statsmodel, ARIMA
Time Series analysis using fpprophet
Conclusion
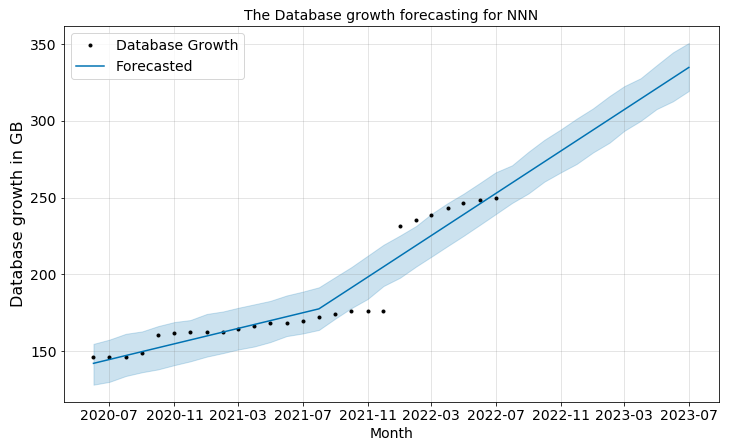
Let me post what could be the out come of doing this. Ex: Database growth and filesystem growth predictions.
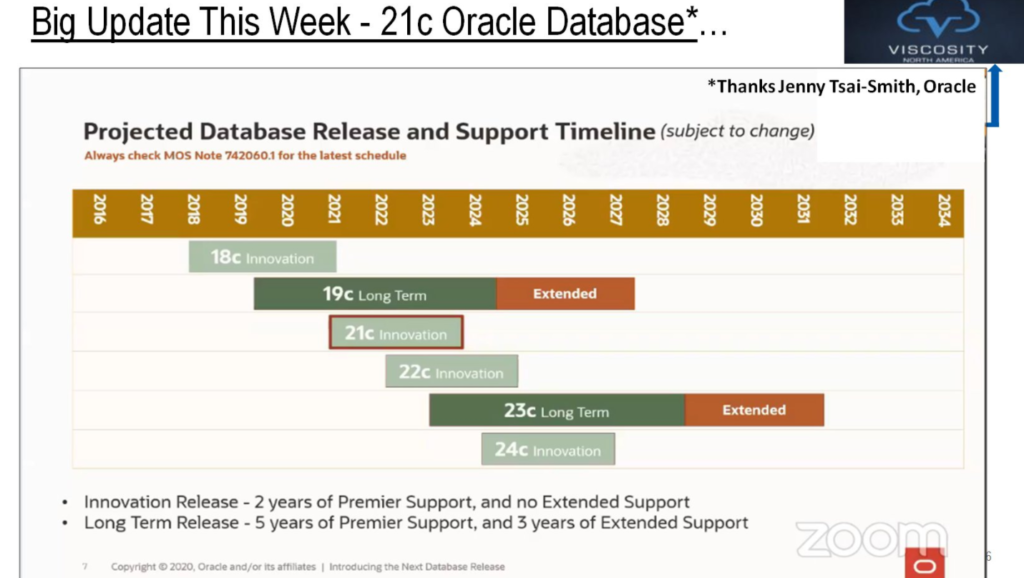
20c Preview edition and its features porting to 21c and here is the update from AIOUG Sangam 2020 and a pictorial representation of upcoming release model. Thanks to Jenny Tsai Smith and Rich Niemiec for sharing this.
Database landscape become vast and we have seen unprecedented growth and usage of many database technologies in the organizations and no one size fit for all tool is available in the market to monitor all of those databases.
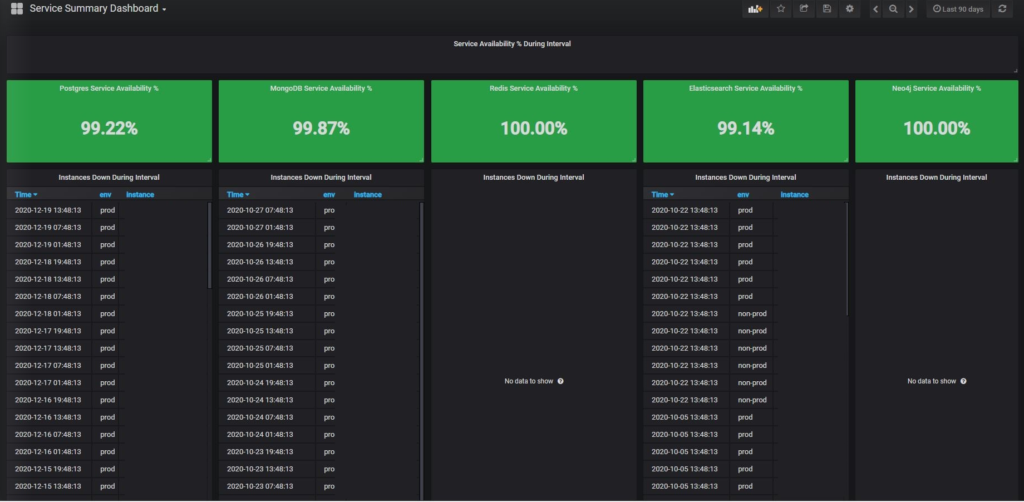
I have started the journey with Prometheus monitoring couple of years back and found its very promising and currently we monitor all of open source databases (as it stand today, MySQL, Postgres, Redis, Neo4j, Cassandra, Mongodb,Elasticsearch). The rich grafana dashboards and the community contribution for exporters is really great
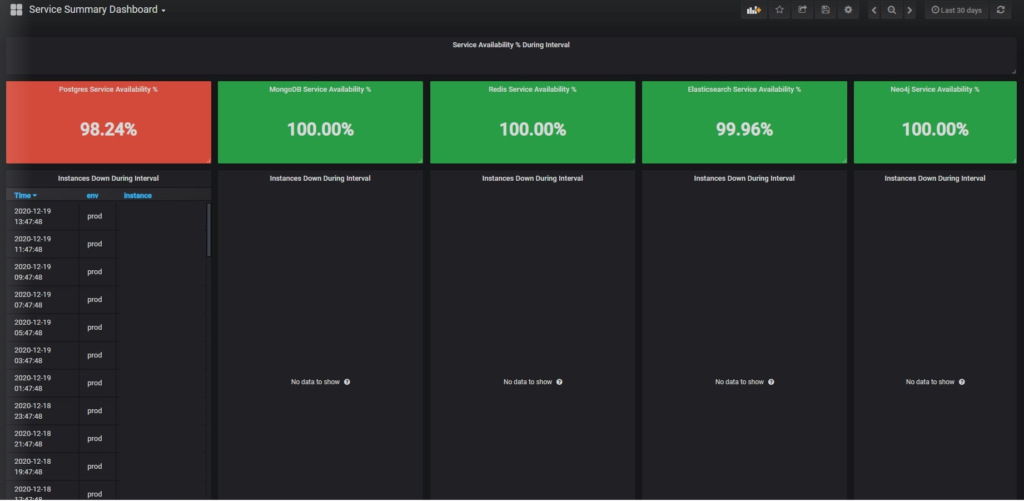
All I did not found is a Service Availability summary of all databases dashboard which tells me the % of database availability during the period which will be a obvious KPI for any Operations team.
I have looked around grafana.com and could not find anything, so started creating my own dashboard and a good learning to me too.
Here are the snippets for the same, which provide summary of service availability of all databases that you are currently tagged to prometheus. All you need to have is the label "tech" and "env" so then all good. The source of the data is "prometheus" you can change once you deploy the dashboard in grafana.
Dashboard json can be downloaded from grafana.com , here

Follow Me!!!