Hello All,
I am speaking this year at AIOUG Sangam 17 and my presenation topic is Oracle Sharding.

Agenda yet to be published and registrations are open.
http://www.aioug.org/sangam17/index.php/registration/registration-details
-Thanks
Suresh
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Hello All, I am speaking this year at AIOUG Sangam 17 and my presenation topic is Oracle Sharding.
Agenda yet to be published and registrations are open. http://www.aioug.org/sangam17/index.php/registration/registration-details -Thanks Suresh
We are back again, this year with more fantastic sessions with another set of Speakers who are well known in Oracle Community and ACE (D).
More Details at http://www.iaoug.com/otn-days.html Registrations are Open and Tickets are Limited Venue: Rydge Hotel World Square, Sydney, Australia Date: Nov 24, From: 8:30 am until 5:30 pm Schedule Details: https://sydneyotnday2017.sched.com/ And I am speaking too about : DevOps for Databases, Register here: https://sydneyotnday2017.sched.com/event/CVLo/devops-for-databases -Thanks Suresh
Hi Many of us know about catctl.pl script to upgrade the databases using parallel slave processes since 12c. Adding to that there is executable in $ORACLE_HOME/rdbms/bin called dbupgrade utility which in turn calls out catctl.pl. There is little known feature which is emulation feature you can run with this utility or script. it displays on screen the same output that you see during an actual upgrade. $ORACLE_HOME/rdbms/catctl.pl -E You can read more from here https://docs.oracle.com/database/122/UPGRD/testing-upgraded-production-oracle-database.htm#UPGRD52882 -Thanks Suresh
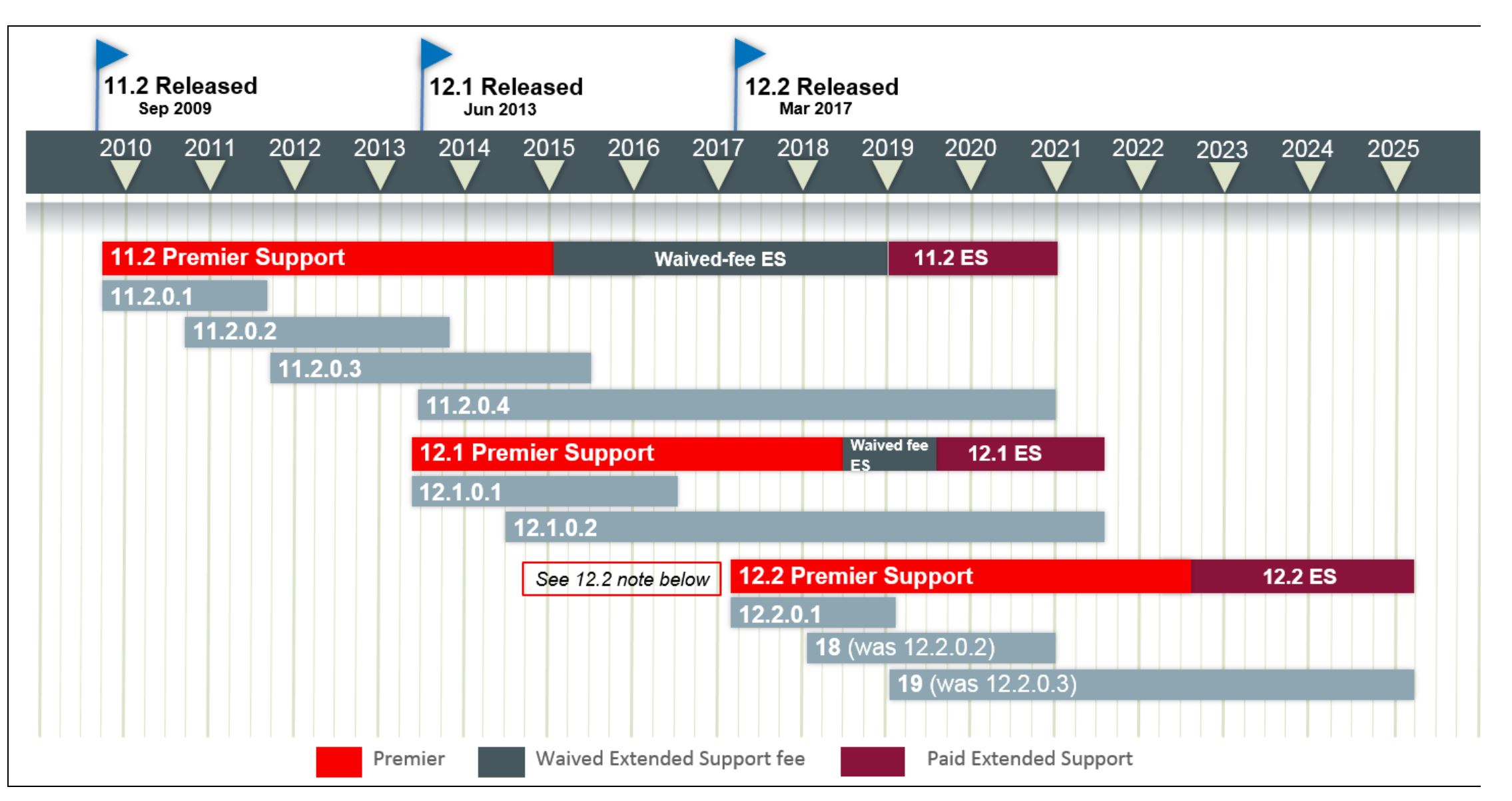
Hello All As you all aware or if not aware of, the next database release i.e 12.2.0.2 is named as 18c and 19c so on. Here is the roadmap from document 742060.1.
-Thanks Suresh Hi All - from previous community discussions, there is a bug in 11.2.0.4 which prevents remote connections as SYS if the SYS account has been locked - this also prevents DG Broker from working correctly, and led to our advice not to lock SYS for DG 11.2.0.4 systems. Oracle have issued a one-off patch for this bug (17732353) long back. This means that if you have any projects currently attempting risk acceptances/dispensations for not locking this sys, we can apply this patch and get sys locked without any affect to DG broker. -Thanks Issue: Post 12C upgrade: Oracle Bug - Virtual Column issue Fix: Set it at session level or system level - fix_control=’16237969:OFF’ Be aware of the virtual column getting created with function based index, which may lead to sub-optimal plans. In 11g , index is getting picked by the oracle optimizer and going with optimal Plan. But in 12c , index is not getting picked by the oracle optimizer and hence it’s going with sub-optimal plan in the query that result in high logical I/O’s and elapse time. Thanks Vasu N, by sharing his findings on this and working with Oracle on the same and he thought of helping to all by sharing this. ######################################### CREATE TABLE TEST_VIRTUAL CREATE TABLE TEST_VIRTUAL_PARENT CREATE INDEX TEST_VIRTUAL_FBI_IDX ON TEST_VIRTUAL (UPPER ("NAME")); ############## ##################### 4 FILTER Filter Predicates: UPPER("NAME")='TEST1' ############## SELECT /*+ OPT_PARAM('_replace_virtual_columns','false') */ ############### While sometime ago, I was looking for a database project requirement to process analytical workload. The organisation choice was Oracle and Developers choice was postgres or vertica. But to handle Vertica we do not have that much of data processing actually needed so the final contenders are Oracle and Postgres. As per licensing guidelines I cannot publish the details of outcome , but I would say the results are not good for me as a Oracle DBA , atleast in processing aggregate functions Oracle for a 2 million record table with more than 200 columns doing a count (*). But indeed we want an enterprise database and stable one not the open source database. Well our data in terms of distinctivity does not change much so some sort of approximation is also fine for us. That is what now in 12.2, with Approximate Query Processing which is as per documentation Approximate Query Processing The 12.2 release extends the area of approximate query processing by adding approximate percentile aggregation. With this feature, the processing of large volumes of data is significantly faster than the exact aggregation. This is especially true for data sets that have a large number of distinct values with a negligible deviation from the exact result. Approximate query aggregation is a common requirement in today's data analysis. It optimizes the processing time and resource consumption by orders of magnitude while providing almost exact results. Approximate query aggregation can be used to speed up existing processing. Oracle provides a set of SQL functions that enable you to obtain approximate results with negligible deviation from the exact result. There are additional approximate functions that support materialized view based summary aggregation strategies. The functions that provide approximate results are as follows: APPROX_COUNT_DISTINCT Approximate query processing can be used without any changes to your existing code. When you set the appropriate initialization parameters, Oracle Database replaces exact functions in queries with the corresponding SQL functions that return approximate results. Parameter that effects the Approximate Query Processing SQL> show parameter approx NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ approx_for_aggregation boolean TRUE approx_for_count_distinct boolean TRUE approx_for_percentile string ALL SQL> When we use the functions , the value returns in hexadecimal to retrieve exact values we need to use associate to_* functions along with materialized views SQL> select unit_code,APPROX_COUNT_DISTINCT_AGG(id) from (select unit_code,APPROX_COUNT_DISTINCT_DETAIL(ID) id from INSIGHTS.TABLE group by unit_code) group by unit_code; UNIT_CODE APPROX_COUNT_DISTINCT_AGG(ID) --------------- ---------------------------------------------------------------------------------------------------------------------------------------------------------------- MHIX115 0D0C0925009E00000000000000A1000000000000000000000040000000000000000000000000000000001000000000000000000000000000000000000000000000040000000000000000000000000000 POIX108 0D0C0DD500740000000000000075000000000000000000000000000080000000000000000000000000001000000000000000000000000000000000000000000000000000000000000000000000000000 PHIX365 0D0C0DD500270000000000000027000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001000000000 So, let me create a MV first with my query CREATE MATERIALIZED VIEW test_approx_agg_mv AS SELECT unit_code, APPROX_COUNT_DISTINCT_DETAIL(id) id FROM INSIGHTS.TABLE GROUP BY unit_code; Then let's access the query as below, as you see the values provided are approximate , when you compare the values with original count (second query)
SQL> SELECT unit_code, TO_APPROX_COUNT_DISTINCT(id) "ids" FROM test_approx_agg_mv ORDER BY unit_code;
UNIT_CODE ids
--------------- ----------
ABR13 2
ABT10 42
ABT13 63
SQL> SELECT unit_code, count(id) from INSIGHTS.TABLE where unit_code in ('ABR13','ABT10','ABT13') group by unit_code;
UNIT_CODE COUNT(id)
--------------- -------------
ABR13 11
ABT13 264
ABT10 202
If i directly try to access the column with regular count we get an error; SQL>SELECT unit_code, count(id) from test_approx_agg_mv ORDER BY unit_code * ERROR at line 1: ORA-00932: inconsistent datatypes: expected - got BLOB SQL> So use the approximation function with associate function to retrieve the data, this works well with MV's rather plain queries -Thanks Suresh
When you run the awr report with non privileged user i.e custom user (even with dba privilege) you may receive the following error.
The possible cases are,
Our case is resolved when we granted the following privilege.
Update: 16-Feb-2017 (Thanks Vasu) The issue still reports, but the following patch is permanent fix.
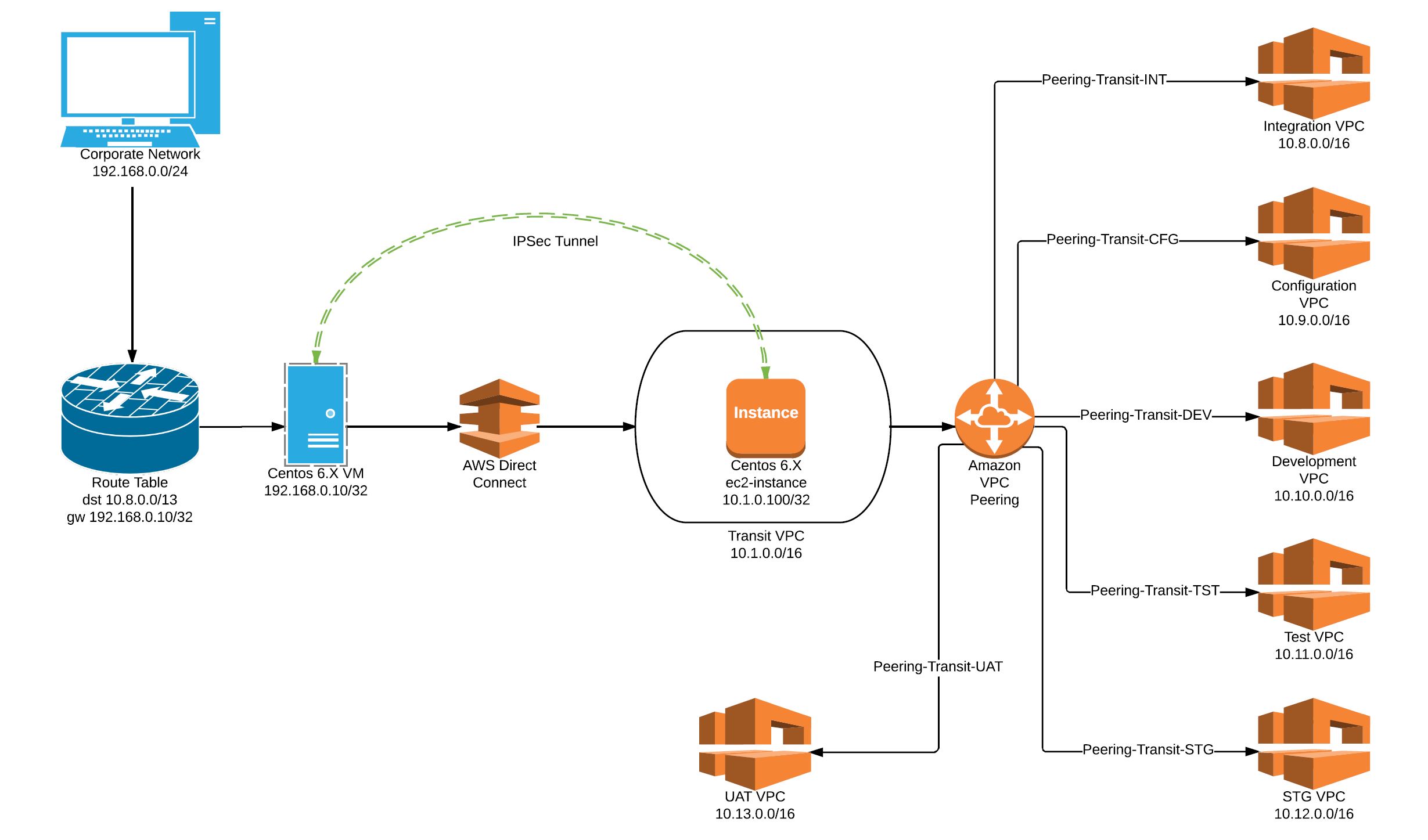
Hope this helps -Thanks Geek DBA Written by Akhil Mathema, We recently incorporated IPSec Tunnel and Transit VPC for our project to simplify our Network connectivity between different AWS Accounts and different VPC's. AWS provides a great flexibility of architecturing your network infrastructure either in terms of Security, flexibility and simplicity. Whether it is from Security or Infrastructure architect perspective, it is ideal to have lesser public facing endpoints in the cloud. An ideal scenario would be to have all non-production resources are to be accessible only via Corporate network. However, it could be challenging if there are multiple non-production environments such as Integration, Configuration, Development, Test, Staging, User-Acceptance Test and so on. The most common practice would be to setup a multiple Direct Connects or VPN connections to various VPCs. This would be less economical and multiple external routes from the corporate network. This can be overcome by the usage of the concept of Transit VPC in conjunction of IPSec tunnel. Take a reference as if you have requirement of setting up a site-to-site VPN between a main and branch office. The end objective would be site office being able to reach file server in local network of main office. The concept of Transit VPC is like all traffic from the corporate network would route to this VPC through a Direct Connect. This would further peer to non-production VPCs. An EC2 instance can be launched in the private subnet of the Transit VPC with IPSec Tunnel configured. On the other hand, either a physical or VM can would be configured with IPSec Tunnel which eventually establishes an IPSec Tunnel over Direct Connect.
I will present a scenario with the following resources:
Here is how it can be configured: Step 1: Establish Direct Connect Ensure you have Direct Connect establish between your corporate network and a transit VPC. This means any resource on Transit VPC are routable via Direct Connect. In this case, test the network connectivity from 192.168.0.0/24 to 10.1.0.0/16 Step 2: VPC peering You can peer VPC as follows: Peering connection name tag: Peering-Transit-DEV VPC (Requester): vpc-id of Transit VPC 10.1.0.0/16 VPC (Accepter): vpc-id of Development VPC 10.10.0.0/16 Once created Peering Connection, you need to “Accept Request” for the peering. Repeat the same process for the rest of the VPCs (Integration, Configuration, Test, Staging and UAT) For example:
Step 3: Configure IPSec Tunnel Using an Open Source tool OpenSwan, you can configure a IPSec Tunnel between a VM in corporate network and an ec2-instance in Transit VPC. In this example, I have used Pre-shared key. The following are the primary configs: $cat /etc/ipsec.d/awsvpc.conf
conn awsvpc
type=tunnel
authby=secret
mtu=1436
keyingtries=3
left=192.168.0.10
leftsubnets={192.168.0.0/24}
leftnexthop=%defaultroute
right=10.1.0.100
rightsubnets={10.8.0.0/13}
rightnexthop=%defaultroute
auto=start
$cat /etc/ipse.d/ipsec.secrets
%any %any : PSK "*********************"
$ cat /etc/ipsec.conf
config setup
nat_traversal=yes
virtual_private=%v4:10.92.168.0.0/24,%v4:10.8.0.0/13
include /etc/ipsec.d/*.conf
Please note: 10.8.0.0/13 would cover the range from 10.8.0.0 to 10.15.255.255
Step 4: Update Static route for non-prod VPCs: All traffic to non-prod VPCs will traverse through an on-prem VM. Hence a static route needs to be configured at the corporate router as follows:
This means any traffic from corporate network 192.168.0.0/24 with destination to 10.8.0.0/16, 10.9.0.0/16, 10.10.0.0/16, 10.11.0.0/16, 10.12.0.0/16 and 10.13.0.0/16 will be routed through a VM 192.168.0.10. Step 5: Configure Route Table: For the given subnet inside Transit VPC, create a route table as follows:
For the given subnet inside Development VPC, create route table as follows:
Repeat same process for rest of the VPC in INT, CFG, TST, STG and UAT. Step 6: Configure Security Groups: Finally, configure Security Groups for each subnet required to be accessible from the corporate network.
On completion of all six steps, you should be able to access AWS resources in non-production VPCs as per defined in Security Groups.
Hope you like this post. -Akhil Mathema Hello, Back in Nov 2016, Microsoft has announced SQL Server on Linux and being a Database enthusiast I would like to hands on and see how it works, but I am been busy with some other projects and could not look into it. Last week I had a conversation with one of my peer in lift and he asked me a question how it works that reminds me this topic again. My first answer to him was , there must be some component or a process which converts a windows calls from SQL platform to Linux abstraction layer which is must, the second in the list was compatibility workarounds. Without looking into any document I was sure about it since Microsoft (or anyone) would never do a overhaul or rewrite SQL Server Platform into Linux. Well, they found themselves with internal projects which offers the bridge between Windows and Linux called "DrawBridge" and evolved something called "SQLPAL" to make sqlserver platform work on linux. You can read more about SQLPAL here from the Microsoft technet blog: https://blogs.technet.microsoft.com/dataplatforminsider/2016/12/16/sql-server-on-linux-how-introduction/ And after reading it, I decided to give a go with installation and see compatibility for features especially with clients and other integration tools we use. I have spinned up an ec2 instance (RHEL 7.4, doc says 7.3) with atleast 2cpu and 7gb of memory with RHEL 7.3 and the script here does the following list of things if your server can connect to internet. I do not want to reinvent the wheel to create my own scripts etc to save sometime, so I have decided to use this script as is.
And Script worked like charm, It took just less than 4 mins (the size of package was 175 m) to install and configure the SQL Server and SQL Server Agent. (contrary to Windows installation of dependencies , .net framework etc etc) Log Here and excerpt of log below Full log : sqlserver_on_linux_install Complete! Configuring firewall to allow traffic on port 1433... sudo: firewall-cmd: command not found sudo: firewall-cmd: command not found Restarting SQL Server... Waiting for SQL Server to start... ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ Microsoft SQL Server 2017 (RC2) - 14.0.900.75 (X64) Jul 27 2017 08:53:49 Copyright (C) 2017 Microsoft Corporation Enterprise Evaluation Edition (64-bit) on Linux (Red Hat Enterprise Linux Server 7.4 (Maipo)) (1 rows affected) Done! And my first look with processes [root@ip-******** ~]# ps -eaf | grep sql mssql 778 1 0 11:32 ? 00:00:00 /opt/mssql/bin/sqlservr mssql 781 778 3 11:32 ? 00:00:07 /opt/mssql/bin/sqlservr root 984 10394 0 11:36 pts/1 00:00:00 grep --color=auto sql Second, connecting database through sqlcmd tool, Add the /opt/msssql-tools/bin to environment [root@ip-****** ~]# echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile [root@ip-****** ~]# source .bash_profile [root@ip-****** ~]# sqlcmd Microsoft (R) SQL Server Command Line Tool Version 13.1.0007.0 Linux Copyright (c) 2012 Microsoft. All rights reserved. usage: sqlcmd [-U login id] [-P password] [-S server or Dsn if -D is provided] [-H hostname] [-E trusted connection] [-N Encrypt Connection][-C Trust Server Certificate] [-d use database name] [-l login timeout] [-t query timeout] [-h headers] [-s colseparator] [-w screen width] [-a packetsize] [-e echo input] [-I Enable Quoted Identifiers] [-c cmdend] [-q "cmdline query"] [-Q "cmdline query" and exit] [-m errorlevel] [-V severitylevel] [-W remove trailing spaces] [-u unicode output] [-r[0|1] msgs to stderr] [-i inputfile] [-o outputfile] [-k[1|2] remove[replace] control characters] [-y variable length type display width] [-Y fixed length type display width] [-p[1] print statistics[colon format]] [-R use client regional setting] [-K application intent] [-M multisubnet failover] [-b On error batch abort] [-D Dsn flag, indicate -S is Dsn] [-X[1] disable commands, startup script, environment variables [and exit]] [-x disable variable substitution] [-? show syntax summary] Next , stop and start and status of service. [root@ip-***** ~]# sudo systemctl restart mssql-server [root@ip-***** ~]# sudo systemctl status mssql-server ● mssql-server.service - Microsoft SQL Server Database Engine Loaded: loaded (/usr/lib/systemd/system/mssql-server.service; enabled; vendor preset: disabled) Active: active (running) since Sun 2017-08-27 11:53:23 UTC; 10s ago Docs: https://docs.microsoft.com/en-us/sql/linux Main PID: 1502 (sqlservr) CGroup: /system.slice/mssql-server.service ├─1502 /opt/mssql/bin/sqlservr └─1504 /opt/mssql/bin/sqlservr Next, I forgot my sa login password, hence reset needed, run a script mssql-conf with set-sa-password it will ask the password. [root@ip-***** ~]# /opt/mssql/bin/mssql-conf set-sa-password Enter the SQL Server system administrator password: Confirm the SQL Server system administrator password: Configuring SQL Server... This is an evaluation version. There are [149] days left in the evaluation period. The system administrator password has been changed. Please run 'sudo systemctl start mssql-server' to start SQL Server. Finally, log into database using sqlcmd [root@ip-****** ~]# sqlcmd -S localhost -U sa -P ***** -d master -Q "select name, database_id from sys.databases" name database_id -------------------------------------------------------------------------------------------------------------------------------- ----------- master 1 tempdb 2 model 3 msdb 4 geekdb 5 (5 rows affected) And also logged through SSMS as well.
You can set some configuration using mssql-conf tool. The following configuration can be done
My Final go to install SSIS package, [root@********* ~]# curl https://packages.microsoft.com/config/rhel/7/mssql-server.repo > /etc/yum.repos.d/mssql-server.repo % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 220 100 220 0 0 100 0 0:00:02 0:00:02 --:--:-- 100 [root@ip-******** ~]# sudo yum install -y mssql-server-is Loaded plugins: amazon-id, rhui-lb, search-disabled-repos packages-microsoft-com-mssql-server | 2.9 kB 00:00:00 Resolving Dependencies Installed: mssql-server-is.x86_64 0:14.0.900.75-1 Complete! Run setup, [root@******* ~]# sudo /opt/ssis/bin/ssis-conf setup The license terms for this product can be downloaded from: https://go.microsoft.com/fwlink/?LinkId=852741&clcid=0x409 The privacy statement can be viewed at: https://go.microsoft.com/fwlink/?LinkId=853010&clcid=0x409 Do you accept the license terms? [Yes/No]:yes Choose an edition of SSIS: 1) Evaluation (free, no production use rights, 180-day limit) 2) Developer (free, no production use rights) 3) Express (free) 4) Web (PAID) 5) Standard (PAID) 6) Enterprise (PAID) 7) I bought a license through a retail sales channel and have a product key to enter. Details about editions can be found at https://go.microsoft.com/fwlink/?LinkId=852748&clcid=0x409 Use of PAID editions of this software requires separate licensing through a Microsoft Volume Licensing program. By choosing a PAID edition, you are verifying that you have the appropriate number of licenses in place to install and run this software. Enter your edition(1-7): 1 Only user in 'ssis' group can run 'dtexec' on Linux. Do you want to add current user into 'ssis' group? [Yes/No]:yes Please logout to reload the group information. SSIS telemetry service is now running. Setup has completed successfully. SSIS Telemetry services running [root@****** ~]# ps -eaf | grep tele
root 2958 1 1 12:26 ? 00:00:00 /opt/ssis/bin/ssis-telemetry
root 2977 2958 20 12:26 ? 00:00:06 /opt/ssis/bin/ssis-telemetry
root 3106 3086 0 12:26 pts/1 00:00:00 grep --color=auto tele
And we can run SSIS package using , will explore that later more.
dtexec /F <package name> /DE <protection password>
Enjoy.. -Thanks Suresh
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


Follow Me!!!