Oracle is releasing a whistle blowing feature in distributed databases (shared nothing architecture) which has been dominated by many other databases in recent years. In upcoming release Oracle 12.2 , the Oracle Sharding feature provides the exact capability of shared nothing architecture with Leader node and shard nodes to distribute the data to nodes and scale upto 1000 shards and without compromising on high availability and relational database properties.
For all other distributed databases in the market, consistency is the main issue , none of them or couple of them provides full consistency due to non implementation of MVCC (undo) in their databases and users has to compromise on data consistency or infact set the consistency level to full but on the other hand loosing performance. But Oracle with its sharding it provide full consistency and also relational schema support.
Oracle Sharding features is rich combination of Connection Pools, ONS, Sharding software (GSM), Partitioning, and Powerful Oracle Database. It is fully ACID complaint as like other RDBMS infact this can be major break through.
The following are the supportable features in Oracle Sharding
- Relational schemas
- Database partitioning
- ACID properties and read consistency (very rich feature when compare to other databases)
- SQL and other programmatic interfaces
- Complex data types
- Online schema changes
- Multi-core scalability
- Advanced security
- Compression
- High Availability features
- Enterprise-scale backup and recovery
The main components of Oracle Sharding are,
- Sharded database (SDB) – a single logical Oracle Database that is horizontally partitioned across a pool of physical Oracle Databases (shards) that share no hardware or software, the schema of this database is partitioned in other database (different hosts)
- Shards - independent physical Oracle databases that host a subset of the sharded databas SDB (schema)
- Global service - database services that provide access to data in an SDB , implementation of general service to a distributed service.
- Shard catalog – an Oracle Database that supports automated shard deployment, centralized management of a sharded database, and multi-shard queries, as like leader node, config instance in mongodb.
- Shard directors – network listeners that enable high performance connection routing based on a sharding key, its like mongos instance for instance and holds the key information which stored in shard catalog.
- Connection pools - at runtime, act as shard directors by routing database requests across pooled connections
- Management interfaces - GDSCTL (command-line utility) and Oracle Enterprise Manager (GUI) to manage shards
What you need to consider before implementing sharding
-
Licensing for Sharding/Partitioning
-
Application suitability, in general OLTP applications suits best with regional data distributed to single node and access through that node.
-
Design of relational schema/table, especially the data distribution key as like other databases.
-
Its not a RAC (shared everything) architecture, its distributed database (shard/partitioning shared nothing)
How the data is distributed?
-
When a table is created with type sharded table one of the column need to specified as distribution key , this is common in any distributed databases
-
The distribution key can be of type consistent,hash,list.
-
The distribution metadata is stored in shard catalog called gsmcatalog
- The table now created in multiple shards aka databases with partitions evenly distributed to each shard.
Data Access flow
-
A service called GSM global service will be created in shard catalog database (sdb) with type and its region affinity etc using gsdctl
-
This service will be used by user/application
-
When user fire a query, The service will connect to shard catalog and get the metadata of distribution and shard directors reroutes the connection to specific nodes or all nodes.
-
The shard catalog acts as leader node/config node.
General Architecture of Oracle Sharding with two shards and one shard catalog database.
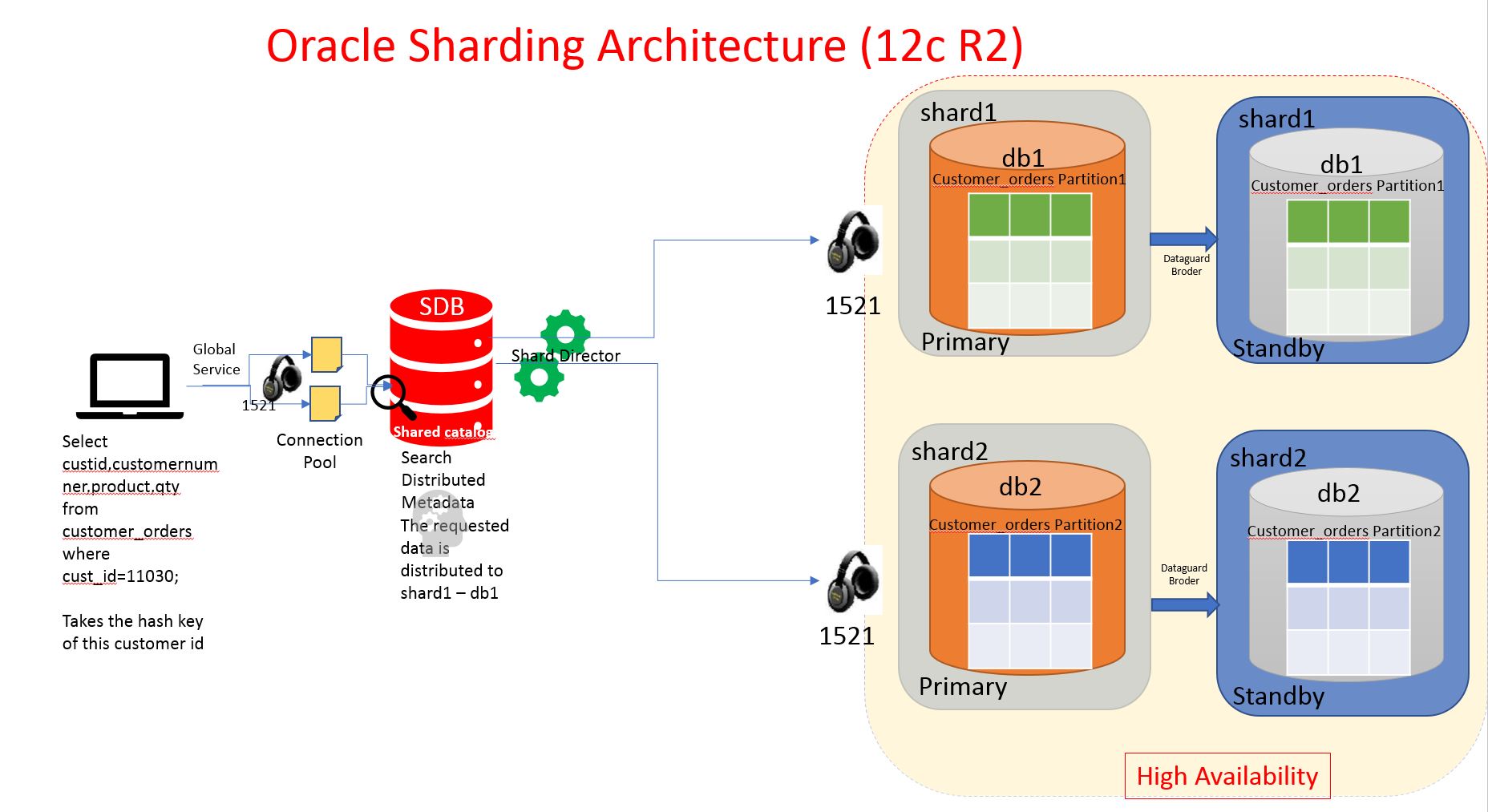
General Software Requirements of Oracle Sharding
-
Oracle Database 12c Release 2 , Non Container Databases
-
Oracle 12c Global Service Manager (Seperate Oracle Home)
-
Oracle Non container databases for shard catalog (SDB) database
Creating a sample Oracle Shard Table.
SQL> ALTER SESSION ENABLE SHARD DDL;
SQL> CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, region VARCHAR2(20)
, class VARCHAR2(3)
, signup DATE
CONSTRAINT cust_pk PRIMARY KEY(cust_id)
)
PARTITION BY CONSISTENT HASH (cust_id)
TABLESPACE SET ts1
PARTITIONS AUTO
;
- When the session has shard ddl enabled,
- The DDL commands will be fired across the shard nodes through database links created in sdb database
- A tablespace ts1 will be created in shardcatalog and shard nodes
- Paritions of table will be created in shard catalog (the first metadata) and shard nodes (exact partitions) distributed evenly.
In next post, I will be showing how to Install and configure the Oracle Sharding and explore more about this exciting feature.
-Thanks
Geek DBA


Follow Me!!!