Hello All,
This is about my weekend rumblings as I was preparing for my next presentations On Kafka + Oracle and hit many road blocks and I thought , I'd better write a post.
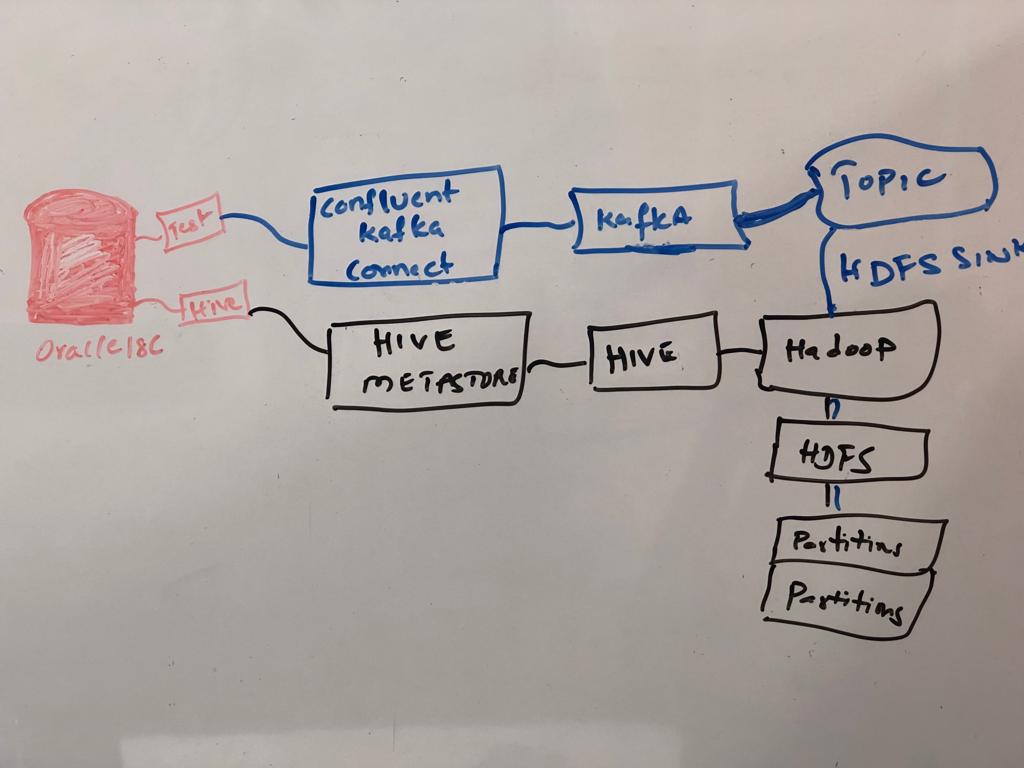
What I am trying to do is,
- Build a vagrant box to test Oracle and Kafka + HDFS with hive integration
- Oracle 18c, Hadoop & Hive & Confluent Kafka installed with Ansible Playbook
- Integrated Oracle -> Kafka Connect & Hive --> HDFS
- So that data/schema changes propagate to kafka topic and store in hdfs, using oracle itself as hive metastore (its causing lot of performance problems)
However, had run into many issues and able to resolve most of them successfully. Here are they. Worth for a individual posts but I will publish a full implementation video post soon.
Issue 1:- Jar Files:- Could not load jar files
ojdbc.jar is not in the configuration directories of Kafka and Hive, placed them in proper directories
[root@oracledb18c kafka-connect-jdbc]# ls -ltr
total 6140
-rw-r--r-- 1 elastic elastic 5575351 Aug 26 2016 sqlite-jdbc-3.8.11.2.jar
-rw-r--r-- 1 elastic elastic 658466 Aug 26 2016 postgresql-9.4-1206-jdbc41.jar
-rw-r--r-- 1 elastic elastic 46117 Aug 26 2016 kafka-connect-jdbc-3.0.1.jar
lrwxrwxrwx 1 root root 40 Feb 23 19:48 mysql-connector-java.jar -> /usr/share/java/mysql-connector-java.jar
lrwxrwxrwx 1 root root 26 Feb 24 13:26 ojdbc8.jar -> /usr/share/java/ojdbc8.jar
[root@oracledb18c kafka-connect-jdbc]# pwd
/opt/confluent/share/java/kafka-connect-jdbc
Issue 1:-Hive Metastore :- org.apache.hadoop.hive.metastore.hivemetaexception: Failed to get schema version.
Make sure MySQL Hive metastore , root/hive user login working properly, hive-site.xml contains proper settings. also the database metastore exists as same in the MySQL.
[vagrant@oracledb18c hive]$ cat /mnt/etc/hive/hive-site.xml.mysql
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://oracledb18c:3306/metastore</value>
<description>JDBC connect string for a JDBC metastore</description>
</property><property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property><property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive@localhost</value>
</property>
Issue 2:- Kafka Connect JDBC: org.apache.kafka.connect.
As such Oracle has number data type not numeric or the jdbc/avro format takes data with precision, a change in table definition is required, instead just number keep it as below
CREATE TABLE users (
id number(9,0) PRIMARY KEY,
name varchar2(100),
email varchar2(200),
department varchar2(200),
modified timestamp default CURRENT_TIMESTAMP NOT NULL
);
Issue 3:- Kafka Connect JDBC:- (org.apache.kafka.connect.runtime.distributed.DistributedHerder:926) java.lang.IllegalArgumentException: Number of groups must be positive.
table.whitelist and tables , not working in oracle jdbc properties , hence turned to query format. here is my properties file
[vagrant@oracledb18c hive]$ cat /mnt/etc/oracle.properties
name=test-oracle-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:oracle:thin:c##test/manager@0.0.0.0:1521/ORCLCDB
#table.whitelist=[C##TEST.USERS]
#tables=[C##TEST.USERS]
query= select * from users
mode=timestamp
incrementing.column.name=ID
timestamp.column.name=MODIFIED
topic.prefix=test_jdbc_
Issue 4:- Kafka Connect JDBC:-org.apache.kafka.connect.
This is again due to Oracle Numeric data type conversion, when we keep mode=timestamp+incrementing it will have the above error, a Jira fix is in progress
Issue 5: Kafka Connect JDBC:- Invalid SQL type: sqlKind = UNINITIALIZED error is shown
oracle.properties file when used query do not keep quotes around.
[vagrant@oracledb18c hive]$ cat /mnt/etc/oracle.properties
name=test-oracle-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:oracle:thin:c##test/manager@0.0.0.0:1521/ORCLCDB
#table.whitelist=[C##TEST.USERS]
#tables=[C##TEST.USERS]
query=" select * from users"query=select * from usersmode=timestamp
incrementing.column.name=ID
timestamp.column.name=MODIFIED
topic.prefix=test_jdbc_
Issue 5:- Hive : Thrift Timeouts- org.apache.thrift.transport.ttransportexception: java.net.SocketTimeoutException: Read timed out (Unresolved)
Hive thrift url timing out due to below issues, I see 100% cpu for all hive thrift connections to Database.
Tasks: 181 total, 4 running, 177 sleeping, 0 stopped, 0 zombie
%Cpu(s): 51.5 us, 0.8 sy, 0.0 ni, 47.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 6808340 total, 93120 free, 2920696 used, 3794524 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1736696 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
20288 oracle 20 0 2542432 87336 80080 R 100.0 1.3 584:06.49 oracleORCLCDB (LOCAL=NO)
Issue 6:- Oracle : 100% CPU , JDBC Connections - 12c Adaptive Plans
I am running 18c and it seems the optimizer_adaptive_plans is set to true by default, disabled.
Issue 7:- Oracle: 100% CPU, JDBC Connections - running for all_objects view and PGA Memory Operation waits (Unresolved)
I see lot of row cache mutex x and PGA Memory Operations,
From 12.2. the latch: row cache objects event renamed as row cache mutex x
Latches are good and light weight, however due to concurrency with JDBC connect and no stats gathers at all (a fresh database) caused this issues, collected schema, fixed, dictionary stats resolved this.
For PGA Memory Operation, seems wen running normal queries with oracle clients there's no issue , however when runs with API based JDBC connections, the memory allocation and unallocation happening.
Also the all_objects query taking long time and seems to be never come out, do not grant DBA at all for the hive metastore user. It will have to query a lot of objects since grants to dba role is vast.
More read here:-https://fritshoogland.wordpress.com/2017/03/01/oracle-12-2-wait-event-pga-memory-operation/
That's it for now.
I will publish a full implementation video soon.
-Thanks
Suresh
nice article on oracle+kafka… looking forward for your full implementation video on kafka
nice article on oracle+kafka… looking forward for your full implementation video on kafka
Hi
https://www.youtube.com/channel/UCWYeyTiYl-vmu9Kg5MOHQDg
Thanks