In MongoDB the high availability is called as basic availability, means in event a primary replicaset lost , the secondary can become primary with in that replicaset. But when the whole shard is down (including all nodes within that replicaset) then there is no High Availability, the data is partially available with respects to the nodes that are available as such of non shared storage, (well its the basis for a distributed processing system )
In this post we will see, What if a Primary Node is down with in replicaset (as like below), how other nodes elect primary
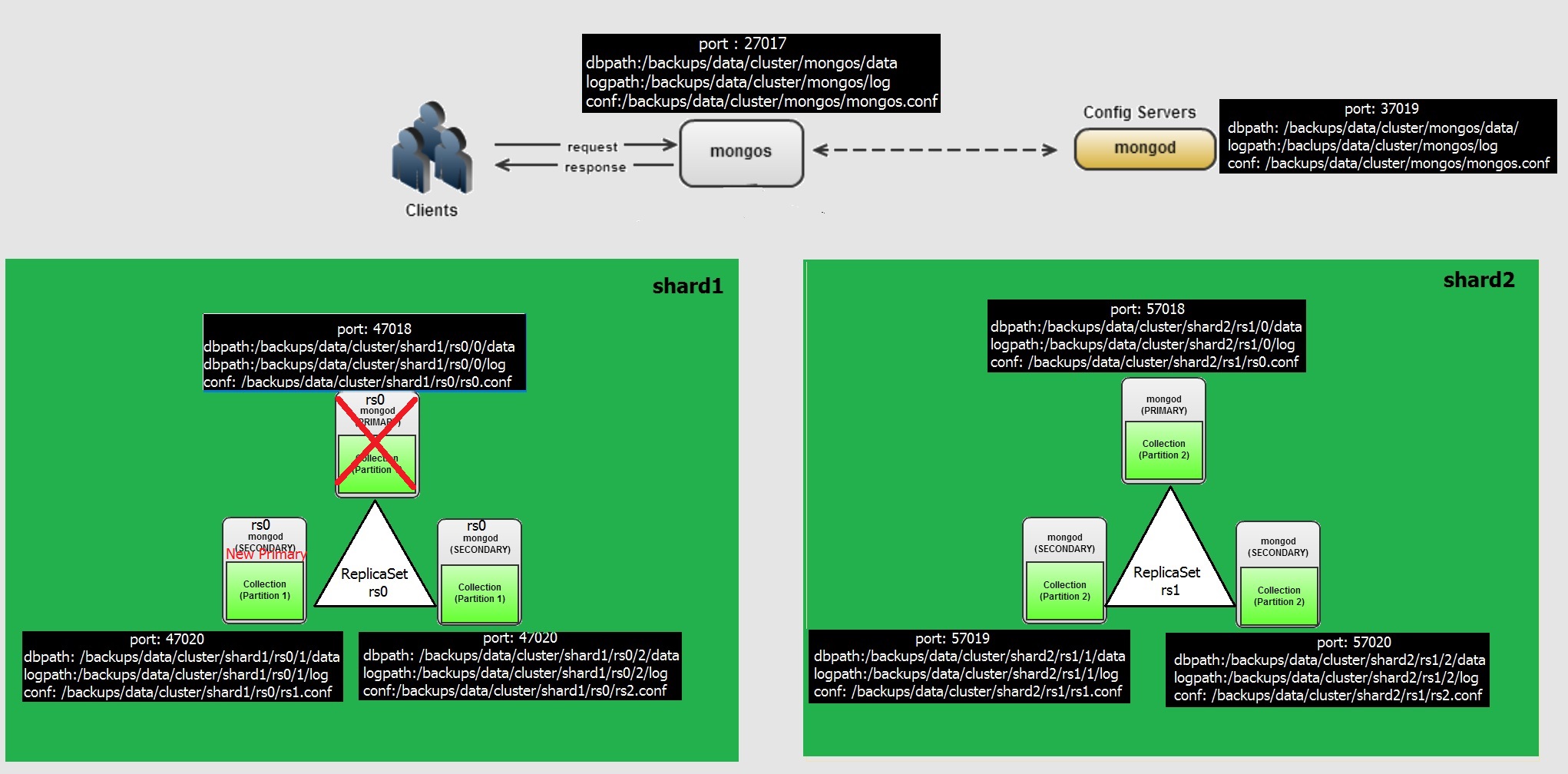
Case 1:- Primary Node eviction with in replicaset
In our configuration, the Replicaset RS0 is sitting on shard1 with nodes 0 (port 47018) , 1 (port 47019) and 2 (port 47020)
So if we kill the process for node 0 in the RS0 , then the secondary nodes can become primary.
Let's check the process for shard1, RS0 and kill the primary node
### Kill the mongo process of replicaset rs0 , node 11-24T02
ps -eaf | grep mongo
root@wash-i-03aaefdf-restore /backups/data/cluster/shard1/rs0/2/logs $ ps -eaf | grep mongo
root 21695 1 1 Nov23 ? 00:18:14 mongod -f /backups/data/cluster/shard1/rs0.conf
root 21678 1 1 Nov23 ? 00:18:14 mongod -f /backups/data/cluster/shard1/rs1.conf
root 21744 1 1 Nov23 ? 00:18:03 mongod -f /backups/data/cluster/shard1/rs2.conf
root 21827 1 0 Nov23 ? 00:05:05 mongod -f /backups/data/cluster/mongoc/mongoc.conf
root 21844 1 0 Nov23 ? 00:05:26 mongos -f /backups/data/cluster/mongos/mongos.conf
root 22075 1 0 Nov23 ? 00:11:31 mongod -f /backups/data/cluster/shard2/rs0.conf
root 22096 1 0 Nov23 ? 00:10:25 mongod -f /backups/data/cluster/shard2/rs1.conf
root 22117 1 0 Nov23 ? 00:10:26 mongod -f /backups/data/cluster/shard2/rs2.conf
root 29699 27585 78 13:24 pts/0 00:06:03 mongo
root 29882 29287 0 13:30 pts/2 00:00:00 mongo localhost:47020
root 29951 29515 0 13:32 pts/3 00:00:00 grep mongo
### Kill the process ID 21695
kill -9 21695
##### Verify the logs for rs0 node 1, 2 (secondary nodes)
As you see below , the Node 0 got killed, the Node 1 with in the replicaset recognises it and the heartbeat failed(in red), then an election mechanism has been happened (in green) and a New primary has been selected and the Node 1 (secondary node) is selected as primary.
tail -20f /backups/data/cluster/shard1/rs0/1/logs/rs0.log
2016-11-24T13:23:30.169+1100 I NETWORK [SyncSourceFeedback] SocketException: remote: (NONE):0 error: 9001 socket exception [RECV_ERROR] server [127.0.0.1:47018]
2016-11-24T13:23:30.169+1100 I REPL [SyncSourceFeedback] SyncSourceFeedback error sending update: network error while attempting to run command 'replSetUpdatePosition' on host 'localhost:47018'
2016-11-24T13:23:30.169+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
2016-11-24T13:23:30.169+1100 I REPL [SyncSourceFeedback] updateUpstream failed: HostUnreachable network error while attempting to run command 'replSetUpdatePosition' on host 'localhost:47018' , will retry
...
2016-11-24T13:23:35.171+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
2016-11-24T13:23:40.114+1100 I REPL [ReplicationExecutor] Starting an election, since we've seen no PRIMARY in the past 10000ms
2016-11-24T13:23:40.114+1100 I REPL [ReplicationExecutor] conducting a dry run election to see if we could be elected
2016-11-24T13:23:40.114+1100 I REPL [ReplicationExecutor] dry election run succeeded, running for election
2016-11-24T13:23:40.115+1100 I REPL [ReplicationExecutor] VoteRequester: Got failed response from localhost:47018: HostUnreachable Connection refused
2016-11-24T13:23:40.115+1100 I REPL [ReplicationExecutor] election succeeded, assuming primary role in term 3
2016-11-24T13:23:40.115+1100 I REPL [ReplicationExecutor] transition to PRIMARY
2016-11-24T13:23:40.115+1100 W REPL [ReplicationExecutor] The liveness timeout does not match callback handle, so not resetting it.
....
2016-11-24T13:23:40.175+1100 I REPL [rsSync] transition to primary complete; database writes are now permitted
2016-11-24T13:23:40.219+1100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:44171 #7 (4 connections now open)
2016-11-24T13:23:40.219+1100 I SHARDING [conn7] remote client 127.0.0.1:44171 initialized this host as shard rs0
2016-11-24T13:23:40.219+1100 I SHARDING [ShardingState initialization] first cluster operation detected, adding sharding hook to enable versioning and authentication to remote servers
2016-11-24T13:23:40.219+1100 I SHARDING [ShardingState initialization] Updating config server connection string to: localhost:37019
2016-11-24T13:23:40.221+1100 I NETWORK [ShardingState initialization] Starting new replica set monitor for rs0/localhost:47018,localhost:47019,localhost:47020
2016-11-24T13:23:40.221+1100 I NETWORK [ReplicaSetMonitorWatcher] starting
### Check the Replicaset Node 2 log
Initially a Socket Exception with Node 0, for port 47018 and connection refused then after a while the Secondary Node recognises that current Primary is Node 1 (in green) and trying to sync. And still trying to reach the node 0 (old primary)
tail -20f /backups/data/cluster/shard1/rs0/2/logs/rs0.log
2016-11-24T13:23:30.168+1100 I NETWORK [SyncSourceFeedback] SocketException: remote: (NONE):0 error: 9001 socket exception [RECV_ERROR] server [127.0.0.1:47018]
2016-11-24T13:23:30.168+1100 I REPL [SyncSourceFeedback] SyncSourceFeedback error sending update: network error while attempting to run command 'replSetUpdatePosition' on host 'localhost:47018'
2016-11-24T13:23:30.168+1100 I NETWORK [conn3] end connection 127.0.0.1:22726 (5 connections now open)
2016-11-24T13:23:30.168+1100 I REPL [SyncSourceFeedback] updateUpstream failed: HostUnreachable network error while attempting to run command 'replSetUpdatePosition' on host 'localhost:47018' , will retry
2016-11-24T13:23:30.169+1100 I NETWORK [conn6] end connection 127.0.0.1:22754 (3 connections now open)
2016-11-24T13:23:30.171+1100 I REPL [ReplicationExecutor] could not find member to sync from
2016-11-24T13:23:30.171+1100 W REPL [ReplicationExecutor] The liveness timeout does not match callback handle, so not resetting it.
2016-11-24T13:23:30.171+1100 I ASIO [ReplicationExecutor] dropping unhealthy pooled connection to localhost:47018
2016-11-24T13:23:30.171+1100 I ASIO [ReplicationExecutor] after drop, pool was empty, going to spawn some connections
2016-11-24T13:23:30.171+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
2016-11-24T13:23:30.171+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
2016-11-24T13:23:30.172+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
....
2016-11-24T13:23:40.172+1100 I REPL [ReplicationExecutor] Member localhost:47019 is now in state PRIMARY
2016-11-24T13:23:40.174+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
....
2016-11-24T13:23:45.173+1100 I REPL [ReplicationExecutor] syncing from: localhost:47019
2016-11-24T13:23:45.174+1100 I REPL [SyncSourceFeedback] setting syncSourceFeedback to localhost:47019
2016-11-24T13:23:45.174+1100 I ASIO [NetworkInterfaceASIO-BGSync-0] Successfully connected to localhost:47019
...
2016-11-24T13:23:45.175+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
### Check the Status , Connect to Node 2 (port 47019) specifically and check replicaset status, output is edited for brevity
As you see in Below, I marked red color for the Node 0, which states it not reachable and Node 1 which becomes current primary and Node 2 still as secondary.
mongo localhost:47019
MongoDB Enterprise rs0:SECONDARY> rs.status()
{
"set" : "rs0",
...
"syncingTo" : "localhost:47019",
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 1,
"name" : "localhost:47018",
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
.....
"lastHeartbeatMessage" : "Connection refused",
"configVersion" : -1
},
{
"_id" : 2,
"name" : "localhost:47019",
...
"stateStr" : "PRIMARY",
"uptime" : 92823,
....
"electionTime" : Timestamp(0, 0),
"electionDate" : ISODate("1970-01-01T00:00:00Z"),
"configVersion" : 1
},
{
"_id" : 3,
"name" : "localhost:47020",
...
"stateStr" : "SECONDARY",
"uptime" : 92824,
...,
"syncingTo" : "localhost:47019",
"configVersion" : 1,
"self" : true
}
],
"ok" : 1
}
MongoDB Enterprise rs0:SECONDARY>
### Lets bring up the Node 0
mongod -f //backups/data/cluster/shard1/rs0/rs0.conf
about to fork child process, waiting until server is ready for connections.
forked process: 30107
child process started successfully, parent exiting
### check the logs of node 1,2 of replicaset rs0
As per logs, it says connection accepted and Node 0 i.e 47018 becomes online and joins as Secondary and Node 1 still primary
tail -20f /backups/data/cluster/shard1/rs0/1/logs/rs0.log
2016-11-24T13:40:33.628+1100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:50596 #15 (8 connections now open)
2016-11-24T13:40:33.628+1100 I NETWORK [conn15] end connection 127.0.0.1:50596 (7 connections now open)
2016-11-24T13:40:33.630+1100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:50600 #16 (8 connections now open)
2016-11-24T13:40:34.667+1100 I ASIO [NetworkInterfaceASIO-Replication-0] Successfully connected to localhost:47018
2016-11-24T13:40:34.668+1100 I REPL [ReplicationExecutor] Member localhost:47018 is now in state SECONDARY
tail -20f /backups/data/cluster/shard1/rs0/2/logs/rs0.log
2016-11-24T13:40:31.730+1100 I REPL [ReplicationExecutor] Error in heartbeat request to localhost:47018; HostUnreachable Connection refused
2016-11-24T13:40:33.628+1100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:32435 #10 (5 connections now open)
2016-11-24T13:40:33.628+1100 I NETWORK [conn10] end connection 127.0.0.1:32435 (4 connections now open)
2016-11-24T13:40:33.731+1100 I ASIO [NetworkInterfaceASIO-Replication-0] Successfully connected to localhost:47018
2016-11-24T13:40:33.731+1100 I REPL [ReplicationExecutor] Member localhost:47018 is now in state SECONDARY
2016-11-24T13:40:39.631+1100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:32445 #12 (6 connections now open)
### check rs.status by connecting to any of the replicaset node directly, now the 47018 the primary node showing as SECONDARY
root@wash-i-03aaefdf-restore /backups/data/cluster/shard1/rs0/1/logs $ mongo localhost:47018
MongoDB shell version: 3.2.1
connecting to: localhost:47018/test
MongoDB Enterprise rs0:SECONDARY> rs.status()
{
"set" : "rs0",
"date" : ISODate("2016-11-24T02:43:18.815Z"),
"myState" : 2,
"term" : NumberLong(3),
"syncingTo" : "localhost:47020",
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 1,
"name" : "localhost:47018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 195,
......
{
"_id" : 2,
"name" : "localhost:47019",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
.......
},
{
"_id" : 3,
"name" : "localhost:47020",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 165,
.....
"ok" : 1
}
MongoDB Enterprise rs0:SECONDARY>
Next Post: Case 2, What if an entire shard is down with all nodes in replicaset.
-Thanks
Geek DBA
Follow Me!!!