Cassandra has three important differences if compared with RDBMS,
- NO-SQL
- Data Stored as Columnar Structure
- Distributed Systems with Nothing Shared Architecture
Cassandra is combination of the Distributed Processing Systems (for high availability and scalability) with NO-SQL (to process unstructured data & schema less structure) & with Column Store(to store wide variety and velocity of data), an adoption of Google BigTable & Amazon DynomoDB.
Let's delve into each of these things.
1. NOSQL - Not Only SQL
NoSQL technologies address narrow yet important business needs. Most NoSQL vendors support structured, semi-structured, or non-structured data which can be very useful indeed. The real value, comes in the fact that NoSQL can ingest HUGE amounts of data, very fast. Forget Gigabytes, and even Terabytes, we are talking Petabytes! Gobs and gobs of data! With clustering support and multi-threaded inner-workings, scaling to the future expected explosion of data will seem a no-brainer with a NoSQL environment in play. Let’s get excited, but temper it with the understanding that NoSQL is COMPLIMENTARY and not COMPETITIVE to ROW and COLUMN based databases. And also note that NoSQL is NOT A DATABASE but a high performance distributed file system and really great at dealing with lots and lots of data
There are three variants of NOSQL,
- Key Value – which support fast transaction inserts (like an internet shopping cart); Generally stores data in memory and great for web. applications that need considerable in/out operations
- Document Store (ex. MongoDB) – which stores highly unstructured data as named value pairs; great for web traffic analysis, detailed information, and applications that look at user behavior, actions, and logs in real time.
- Column Store (Cassandra) – which is focused upon massive amounts of unstructured data across distributed systems (think Facebook & Google); great for shallow but wide based data relationships yet fails miserably at ad-hoc queries .
2. Data Stored as Columnar Structure
Imagine a Row vs Column Structure
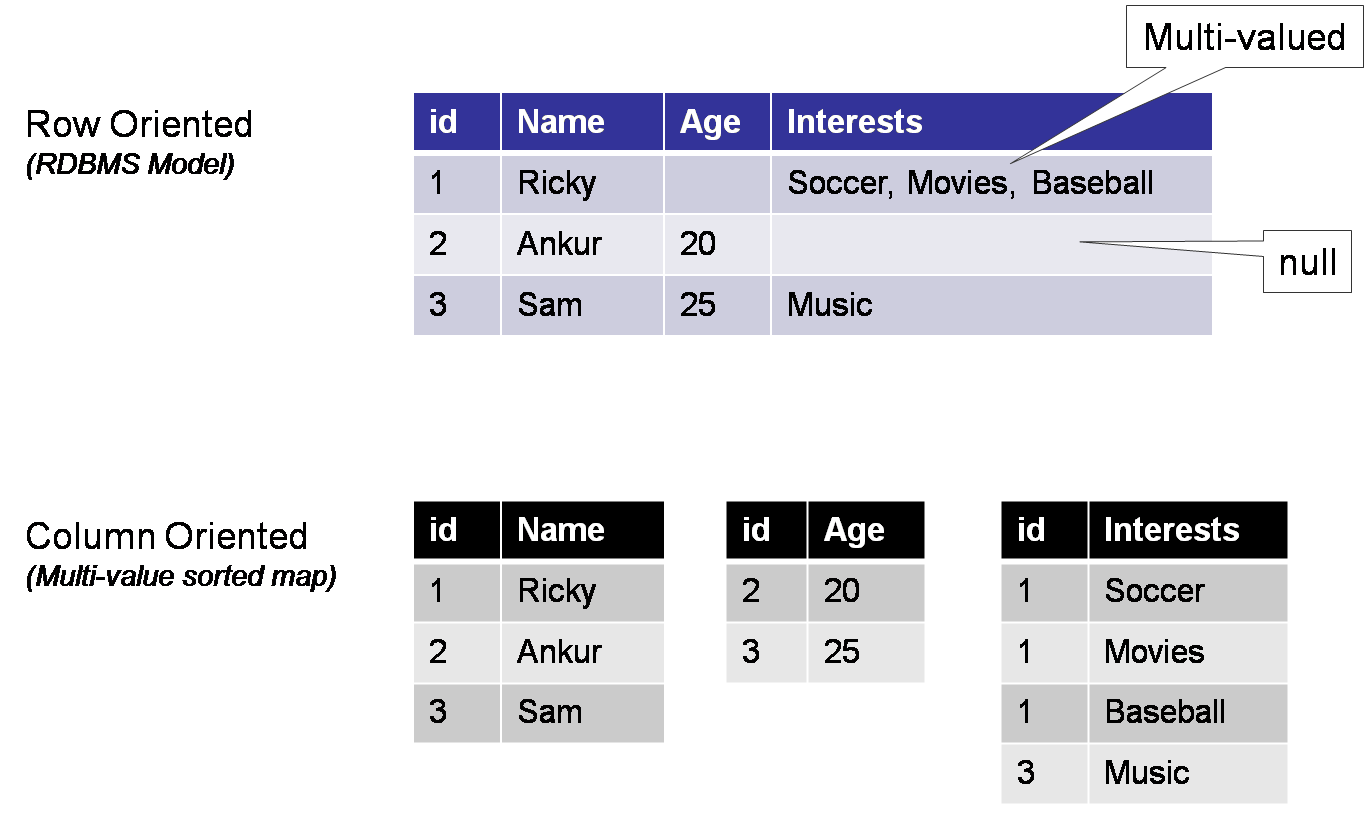
Creating a Table in RDBMS Creating a Table using CQL (Thirft naming convention: Column Family) with Column Database like Cassandra
Create table emp Create table emp
(id number primary key, (id int,
name varchar2(10), name text,
age number, age number,
interests varchar2(100)); interests text,
PRIMARY KEY((id), name, age, interests)
The Nomenclature is as follows,
- id: The Partition Key is responsible for data distribution across your nodes. Data sorted in the Columns with Key value in each separate files on the disk.
- name:age:interests: The column key values that store for each partition
3. Distributed Systems with Shared Nothing Architecture
- For Cassandra, the usage of distributed system is Shared Nothing Architecture where in Oracle RAC Architecture uses Shared Disk Architecture.
- As you see, the data is stored in each node locally
- And unlike RAC master-slave architecture(cluster & database instance level), this is peer-peer architecture and every node act as coordinator
- As such the data is stored locally , data will be evenly distributed (stripes) to each node when data writes into tables.
- Each Node contains the Token Range to accept and store data
- Token Range is determined by Partition Schemes used by Cassandra Random Partitioner, Murmur partitioner, OrderPreserving Partitioner etc.
- If a node is added/deleted, as like in ASM Diskgroup Re-balancing, Cassandra will re-balance node data to other nodes by rearranging the token assigned to each node.

- But as such the data stores locally, there is likely hood that Data may lost in case of failure
- To avoid this, while inserting the data , Cassandra uses Replicaton Factor for each Schema/Keyspace
- So that all tables in that schema/keyspace will have the data mirrored (ASM Disk Mirroring) across nodes
- This avoids single point of failure and as well as contention on Read/Write I/O.
Cassandra mirrors Data to Nodes based on Two things, Strategy and replication factor
- SimpleStrategy (Single Data Centre), NetworkTopology Strategy with multiple DC or Single DC with specific identification of IP & Servers, so that data mirrors across data centres.
- Replication Factor: How many copies of data should be maintained in cluster.
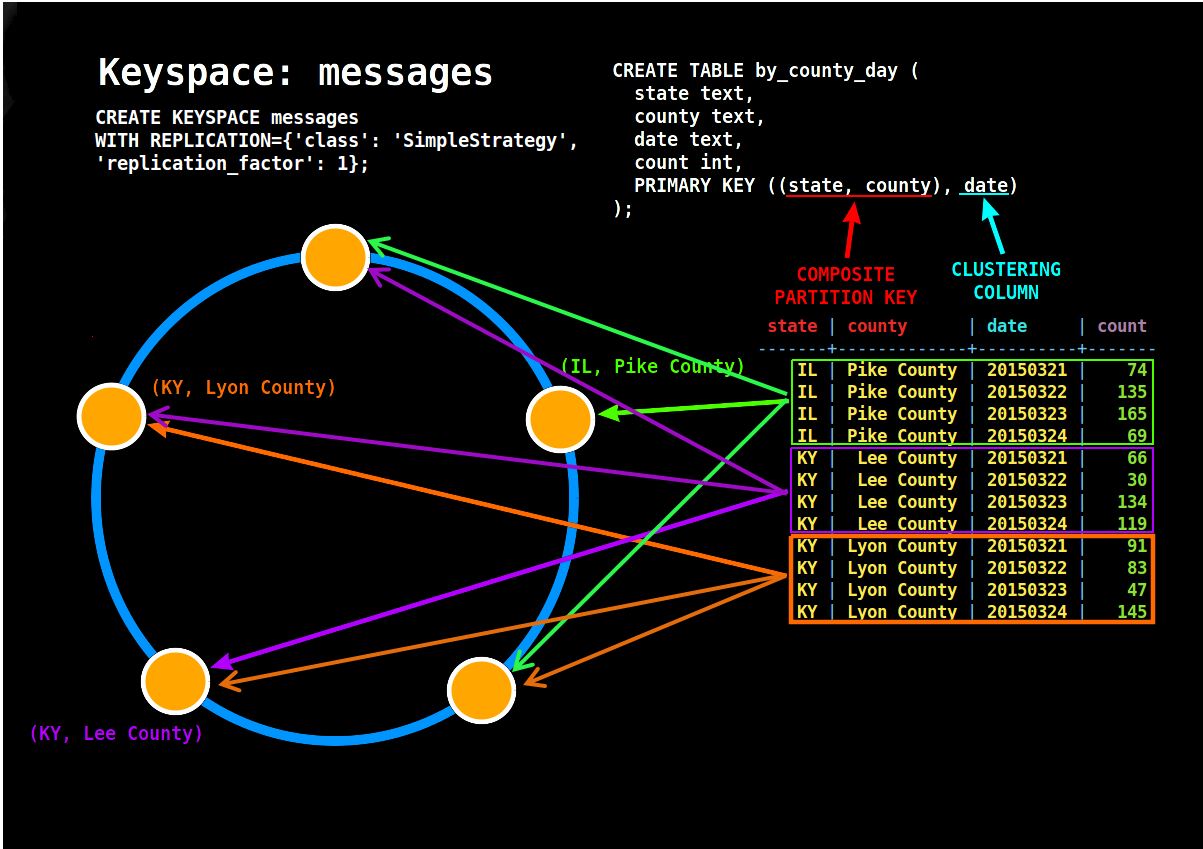
In the below diagram, with 5 Node Cassandra , we have created a Keyspace Called Messages with replication placement strategy of Simple & Replication Factor 1
Replication Factor: 1 : In this case 1, means the data will be not be mirrored and you see the IL, KY with their county has been written to different nodes
In case of failure of a node, the data in that node will not be available to the clients means a data loss/unavailability.

Take another example, In the below diagram, with 5 Node Cassandra , we have created a Keyspace Called Messages with replication placement strategy of Simple & Replication Factor 3
Replication Factor: 3 : In this case 3, means the data will be mirrored to three nodes at least in the cluster and you see the IL, KY with their county has been written to different node,
In case of failure of a node, the data in that node will not be available but the co-ordinator will get the data from other replicas.
But in case of data centre loss, it is likely hood that whole cluster is not available.
Take another example, In the below diagram, with 5 Node Cassandra , we have created a Keyspace Called Messages with replication placement strategy of NetworkTopology Strategy & Replication Factor as, for us-west data center is 3 and us-east is 2.
As you see below, the data is spawned/mirrored three copies in us-west and two copies in us-east

That's all about in this post, There's nothing new I have written above most of things available in Internet, but to have a series of posts I would like to have an introduction first and then dig into more for DBA's.
Lets take a closer look at architecture of Cassandra and its components for each node in next post.
Image Courtesy: Random Blogs in internet & Apache Cassandra website.
GeekDBA
Follow Me!!!