In the previous post we saw when a node in replicaset lost, the secondary nodes become a primary and all data is available.
In this post we will see what if , if a shard is completely lost. A picture looks like this.
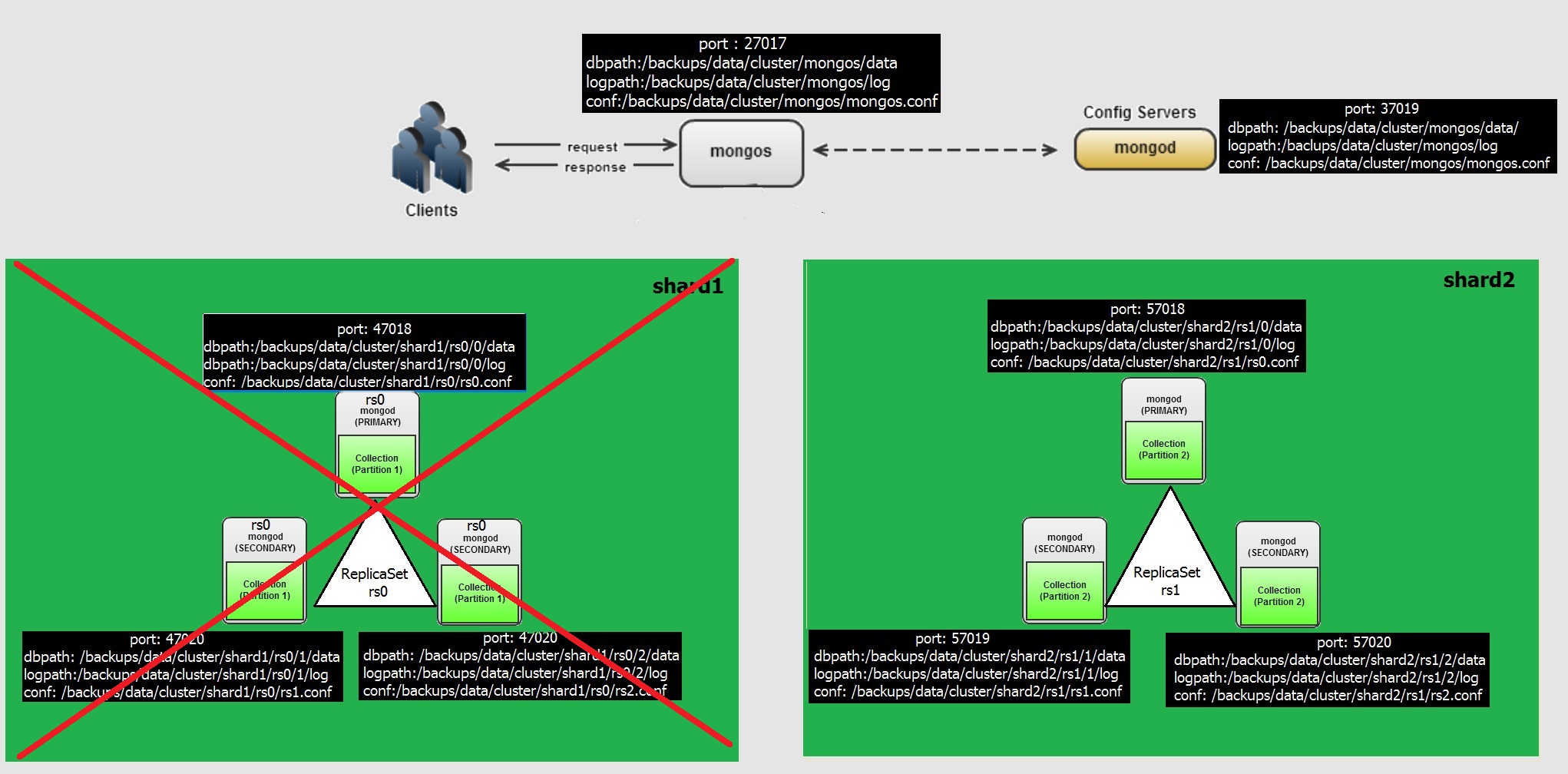
As the data is distributed across the shards, if a shard with all nodes belong to that shard, the Data is partially available. Thats why perhaps MongoDB called Basic Availability instead of High Availability (as of my understanding, anyone knows better than this can correct me as well)
Lets lose a shard, we have shard1 with three nodes of replicaset, lets kill the process.
root@wash-i-03aaefdf-restore ~ $ ps -eaf | grep mongo
root 4462 4372 0 13:02 pts/0 00:00:00 grep mongo
root 21678 1 0 Nov23 ? 01:35:23 mongod -f /backups/data/cluster/shard1/rs1.conf
root 21744 1 0 Nov23 ? 01:32:55 mongod -f /backups/data/cluster/shard1/rs2.conf
root 21827 1 0 Nov23 ? 01:17:21 mongod -f /backups/data/cluster/mongoc/mongoc.conf
root 21844 1 0 Nov23 ? 00:38:52 mongos -f /backups/data/cluster/mongos/mongos.conf
root 22075 1 0 Nov23 ? 01:32:45 mongod -f /backups/data/cluster/shard2/rs0.conf
root 22096 1 0 Nov23 ? 01:21:05 mongod -f /backups/data/cluster/shard2/rs1.conf
root 22117 1 0 Nov23 ? 01:21:10 mongod -f /backups/data/cluster/shard2/rs2.conf
root 30107 1 0 Nov24 ? 01:11:14 mongod -f /backups/data/cluster/shard1/rs0.conf
### Kill the process highlighted , this eventually bring down the shard
root@wash-i-03aaefdf-restore ~ $ kill -9 30107 21678 21744
### Lets log to mongos instance and check the sharding status
Let me explain the out put
- This has two shard with three nodes in each rs0 and rs1 replicaset.
- Last reported error says that rs0 replicaset in shard1 is not reachable of any nodes.
- Database Foo has sharding enabled
- Under Foo Database testData table is partitioned across nodes with three each of these chunks distributed
MongoDB Enterprise mongos> sh.status()
--- Sharding Status ---
sharding version: {
"_id" : 1,
....
}
shards:
{ "_id" : "rs0", "host" : "rs0/localhost:47018,localhost:47019,localhost:47020" }
{ "_id" : "rs1", "host" : "rs1/localhost:57018,localhost:57019,localhost:57020" }
..
balancer:
...
Last reported error: None of the hosts for replica set rs0 could be contacted.
Time of Reported error: Fri Dec 09 2016 13:03:35 GMT+1100 (AEDT)
..
databases:
{ "_id" : "foo", "primary" : "rs0", "partitioned" : true }
foo.testData
shard key: { "x" : "hashed" }
unique: false
balancing: true
chunks:
rs0 3
rs1 3
{ "x" : { "$minKey" : 1 } } -->> { "x" : NumberLong("-6932371426663274793") } on : rs1 Timestamp(3, 0)
{ "x" : NumberLong("-6932371426663274793") } -->> { "x" : NumberLong("-4611686018427387902") } on : rs0 Timestamp(3, 1)
{ "x" : NumberLong("-4611686018427387902") } -->> { "x" : NumberLong("-2303618986662011902") } on : rs0 Timestamp(2, 8)
{ "x" : NumberLong("-2303618986662011902") } -->> { "x" : NumberLong(0) } on : rs0 Timestamp(2, 9)
{ "x" : NumberLong(0) } -->> { "x" : NumberLong("4611686018427387902") } on : rs1 Timestamp(2, 4)
{ "x" : NumberLong("4611686018427387902") } -->> { "x" : { "$maxKey" : 1 } } on : rs1 Timestamp(2, 5)
### As we killed the mongod process for RS0 replicaset, lets take a look of Primary node log file replicaset RS1 in shard2
It reports , all nodes in replicaset rs0 are down and triying to keep pooling.
root@wash-i-03aaefdf-restore /backups/data/cluster/shard2/rs1/0/logs $ tail -20f rs1.log
2016-12-09T13:04:02.553+1100 W NETWORK [ReplicaSetMonitorWatcher] Failed to connect to 127.0.0.1:47020, reason: errno:111 Connection refused
2016-12-09T13:04:02.553+1100 W NETWORK [ReplicaSetMonitorWatcher] Failed to connect to 127.0.0.1:47018, reason: errno:111 Connection refused
2016-12-09T13:04:02.553+1100 W NETWORK [ReplicaSetMonitorWatcher] No primary detected for set rs0
2016-12-09T13:04:02.553+1100 I NETWORK [ReplicaSetMonitorWatcher] All nodes for set rs0 are down. This has happened for 6 checks in a row. Polling will stop after 24 more failed checks
This means, another shard i.e shard2 which having replicaset rs1 and its data is available. This is what partial data availability. Lets query the table with random data, so we can see any errors
### If I want to see all documents aka rows , this will throw an error right away saying rs0 cannot be contacted.
mongo localhost:27017
MongoDB Enterprise mongos> db.testData.find()
Error: error: {
"ok" : 0,
"errmsg" : "None of the hosts for replica set rs0 could be contacted.",
"code" : 71
}
MongoDB Enterprise mongos>
### Lets find the random data, find the document with x=750000, throws errors , so it seems that this particular document is in replicaset rs0
MongoDB Enterprise mongos> db.testData.find({x : 750000})
Error: error: {
"ok" : 0,
"errmsg" : "None of the hosts for replica set rs0 could be contacted.",
"code" : 71
}
### Lets find the document for 1000000, see its available and shown the row. as such this document is available in replicaset rs1
MongoDB Enterprise mongos> db.testData.find({x : 1000000})
{ "_id" : ObjectId("58362c23c5169089bcd6683e"), "x" : 1000000 }
### Lets find the document for 900000, again this row got an error
MongoDB Enterprise mongos> db.testData.find({x : 900000})
Error: error: {
"ok" : 0,
"errmsg" : "None of the hosts for replica set rs0 could be contacted.",
"code" : 71
}
### Lets find for row 900001, just a next row of previous one. Ohoa, its available no error.
MongoDB Enterprise mongos> db.testData.find({x : 900001})
{ "_id" : ObjectId("58362bcbc5169089bcd4e19f"), "x" : 900001 }
MongoDB Enterprise mongos>
### Some more random tests, few rows resulted and few not.
MongoDB Enterprise mongos> db.testData.find({x : 840000 })
{ "_id" : ObjectId("58362b98c5169089bcd3f73e"), "x" : 840000 }
MongoDB Enterprise mongos> db.testData.find({x : 930000 })
{ "_id" : ObjectId("58362be5c5169089bcd556ce"), "x" : 930000 }
MongoDB Enterprise mongos> db.testData.find({x : 250000 })
Error: error: {
"ok" : 0,
"errmsg" : "None of the hosts for replica set rs0 could be contacted.",
"code" : 71
}
So plan the shards or shard key in such a way that you achieve high availability even in case complete loss.
-Thanks
Geek DBA
Follow Me!!!