High Availability is the key for any distributed systems which includes the load balancing. In High Availability , one can think of Active-Active Nodes or Active - Passive Nodes, Cassandra and Oracle RAC falls into the first category, active-active mode. But Cassandra have important architectural differences unlike oracle rac
- Cassandra does not use shared storage, this helps the data can be distributed across nodes which is classic example of distributed storage processing.
- Cassandra does not adhere to Master Slave technology, this helps to reduce the communication with master node every time at database level and at cluster level also
- Cassandra does not use private network, indeed node communication happens using common network with gossip protocol
- Cassandra does not do a heart beat to every node in the cluster which can be a clumsy network congestion as like in Oracle RAC
Consider this example of Cluster Network in Oracle RAC, where each node pings to other node in the cluster and that is the reason you must have low latency network used for RAC

But with Cassandra every node will be configured to know about a seed node rather whole nodes in cluster, consider this example which reduces the foot print of cluster network usage but also effective communication is possible.
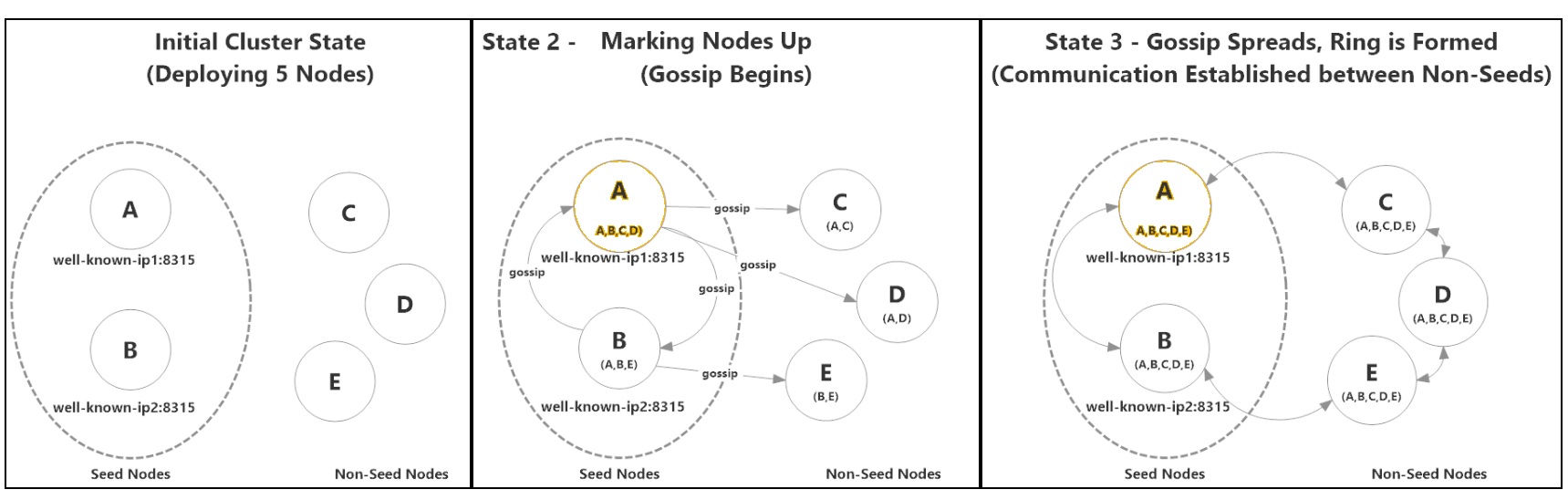
In the cluster, A and B configured as seed nodes and C,D,E configured as non seed nodes (in cassandra.yaml file for each node), so C & D nodes are configured to reach A and E node is configured to reach B for a gossip information i.e node availability information.
When cluster starts, A, B nodes are up and see each other and C,D,E configured to reach seed nodes, once they warm up and each node knows about other nodes
Cassandra uses Gossip Protocol to reach nodes every 2 seconds and update about the availability of nodes.
Gossip is a peer-to-peer communication protocol in which nodes periodically exchange state information about themselves and about other nodes they know about. The gossip process runs every second and exchanges state messages with up to three other nodes in the cluster. The nodes exchange information about themselves and about the other nodes that they have gossiped about, so all nodes quickly learn about all other nodes in the cluster. A gossip message has a version associated with it, so that during a gossip exchange, older information is overwritten with the most current state for a particular node.
To prevent problems in gossip communications, use the same list of seed nodes for all nodes in a cluster. This is most critical the first time a node starts up. By default, a node remembers other nodes it has gossiped with between subsequent restarts. The seed node designation has no purpose other than bootstrapping the gossip process for new nodes joining the cluster. Seed nodes are not a single point of failure, nor do they have any other special purpose in cluster operations beyond the bootstrapping of nodes.
In my CCM (developer mode) Node configurations the nodes 1,2,3 configured as seed nodes
root@wash-i-16ca26c8-prod ~/.ccm/geek_cluster/node1/resources/cassandra/conf $ grep seed cassandra.yaml
seed_provider:
- seeds: 127.0.0.1,127.0.0.2,127.0.0.3
And for one Node1 the heartbeat information from Gossipinfo shows every 2 seconds.
root@wash-i-16ca26c8-prod /scripts/db_reconfiguration $ ccm node1 nodetool gossipinfo | grep heartbeat
heartbeat:122773
heartbeat:122775
heartbeat:122764
heartbeat:122776
Every 2 seconds considered as a heartbeat information, and failure detector (using PhiFailureDetection method of magical number 0.434) and cassandra default setting of phi_convict_threshold =8
So it means at every 2 seconds the heartbeat calculates and record last time sample if it exceed from convict thresholds, giving an example, 8/0.434 = 18.4 seconds, that mean the node will be marked down after 18.4 seconds.
In this way, Cassandra ensures the nodes are reachable and available to the cluster and process.
Follow Me!!!