Shared Disk architecture in RAC where the data is shared across the nodes and at any point of time , every instance will give the same data using cache fusion.
But in Cassandra, the important part is storage is not shared storage, instead its sharded means partitioned and stored in each node.
And when you see RAC architecture we see an horizontal landscape (the hub nodes), like below figure 1, where in Cassandra nodes formed as ring (the peer architecture or hub-leaf spoke technology). In a ring architecture every node acts as coordinator there is no master in cluster unlike RAC.
Note: In 12c we use the same mechanism called Flex Cluster, but still the Hub Nodes aka database uses shared storage. Do not confuse with it.
Diagrams RAC & Cassandra

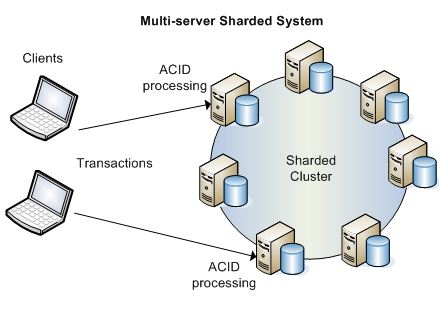
RAC 12c Flex Cluster Architecture Cassandra Sharded Cluster Nodes
Well, if the data is not shared , we as a DBA the common questions that come to our mind are, 🙂
1. How does the data is distributed to the nodes?
2. How does nodes see a consistent data if a read happens?
3. How does node knows if a write happen in one node the other node knows about it?
4. How about data availability?What if the one of the node corrupted or disk failed?
Before to answer this questions, Lets catch up our ASM Diskgroup Mirroring and Striping methods
ASM uses diskgrup level redundancy aka mirroring with Normal (two copies) and High (three copies), so at any time it maintains the data that stored in data diskgroup that many copies. Even a diskgroup/disk failure will not have any data loss.
ASM uses disk level striping so it evenly distribute the data to the number of disks in that diskgroup, when a disk added or deleted the data is distributed to other disk first called re-balancing and then allow disk operations on it. This ensures the data can be read / write evenly to avoid a single point of contention on disks.
Keeping those in mind, Just mark yourself rather diskgroup level, in Cassandra the data is maintained at node level replication and striping. So each node store its own set of data and may be a replicated data of other nodes.
In Cassandra, Mirroring is achieved by Replication Factor and Striping is achieved by Token Range of the nodes called Partitioner ( I am not covering Vnodes here )
Partitioner/Tokens:- Cassandra uses a hashing mechanism to assign a token range for a node. When a node is added and deleted one must re-assign the tokens (not the vnodes configuration) so that data will be redistributed to the other/new nodes as like the ASM Diskgroup Rebalancing. Now with token in place for each node, there is another thing that required is table level partition key, which is based on a column to store certain partitioned data into a separate node. And then while any DML operation performed that row will be hashed and checked with node token range and insert into that particular node. In this way each node has a non shared data means a part of data for a table.
Cassandra uses different types of hash mechanism to provide token to nodes and A partitioner determines how data is distributed across the nodes in the cluster (including replicas). Basically a partitioner is a function for deriving a token representing a row from its partion key, typically by hashing. Each row of data is then distributed across the cluster by the value of the token. Both the Murmur3Partitioner and RandomPartitioner use tokens to help assign equal portions of data to each node and evenly distribute data from all the tables throughout the ring or other grouping, such as a keyspace. This is true even if the tables use different partition key, such as usernames or timestamps. Moreover, the read and write requests to the cluster are also evenly distributed and load balancing is simplified because each part of the hash range receives an equal number of rows on average.
You can set the partitioner type in cassandra.yaml file using
Murmur3Partitioner: org.apache.cassandra.dht.Murmur3PartitionerRandomPartitioner: org.apache.cassandra.dht.RandomPartitionerByteOrderedPartitioner: org.apache.cassandra.dht.ByteOrderedPartitioner
Mirroring/Replication :- Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor.
Replication Factor can be configured at Key Space Level. i.e A tablespace/schema level, and then each object/table in that Keyspace will maintain that Replicas in nodes. A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. However, you can increase the replication factor and then add the desired number of nodes later.
Replication Strategies can be determined by Using class option at Key Space Level so that each data center will maintain a set of data replicas.
Two replication strategies are available:
SimpleStrategy: Use only for a single data center and one rack. If you ever intend more than one data center, use theNetworkTopologyStrategy.NetworkTopologyStrategy: Highly recommended for most deployments because it is much easier to expand to multiple data centers when required by future expansion.
With above, look at the example with replication factor 3 with single and multiple datacenter.

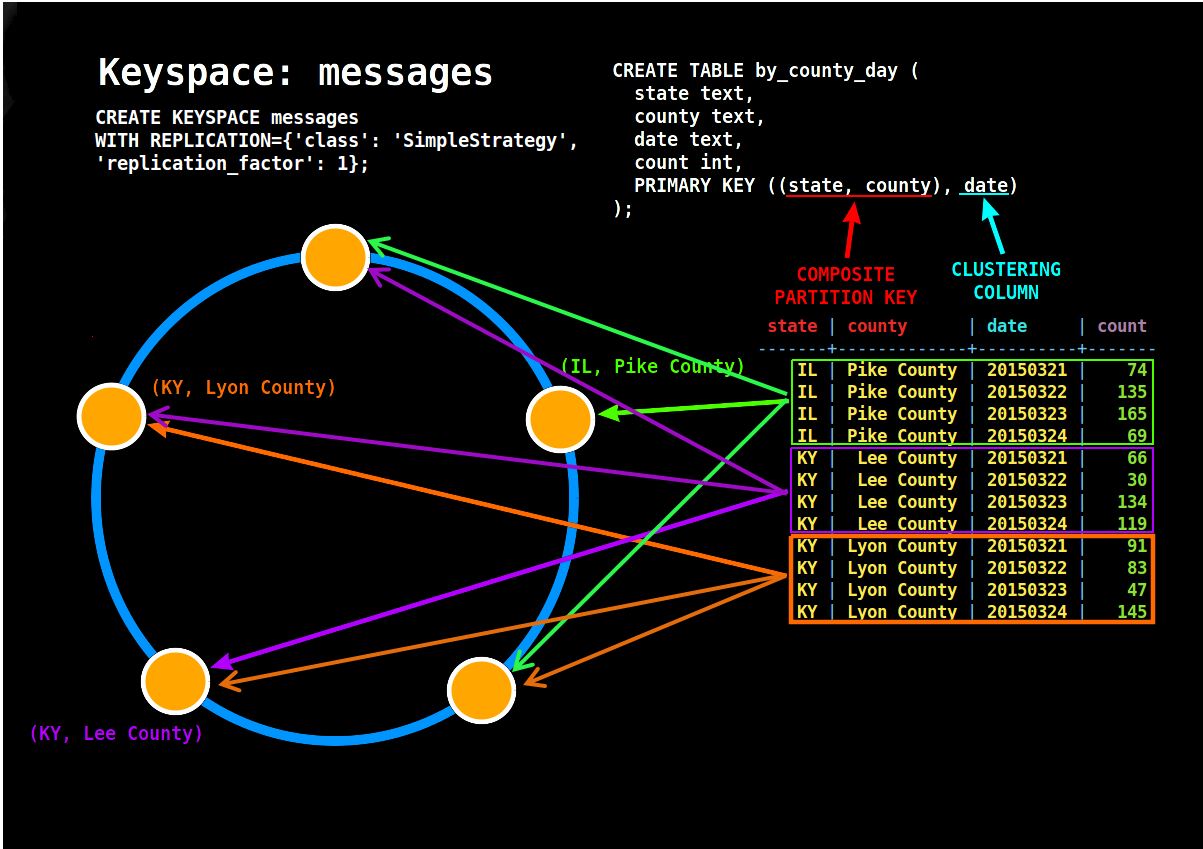
Now lets answer the questions above.
1. How does the data is distributed to the nodes?
Ans: Data Distribution of nodes is based on Token Range assigned to the node. So each node stores different data.
2. How about data availability?What if the one of the node corrupted or disk failed?
Ans: As such the data is replicated to other nodes, even if a node / disk failed the other nodes can get the data. This way data high availability is maintained.
3. As if the data is not shared how about read consistency and write consistency.
Ans: Cassandra Maintains the eventual consistency in forms of multiple read requests to the nodes if it sees the data digest is not matching. So it try to read the most recent data from other replicated nodes.
Read Next post for Read/Write Paths.
Thanks
Geek DBA
Follow Me!!!