Introduction to server pool, (the real meaning of ‘g’ in the oracle’s advertisement since 10g)
Very long post, take free time to read and to get a clear understanding…..
Grid computing is a concept within Oracle database which has been there since 10g. The basic meaning of grid computing is to divide the hard coupling of the availability of a resource over the machines thus letting the resources be available on a ‘wherever and whenever’ kind of basis. This means that there shouldn’t be a restriction on a said resource which must be present on a specific machine itself or can only be accessed from a specific machine. The very same concept is enhanced in 11.2 RAC with the introduction of Server Pools.
Server Pools allow the same functionality of logically dividing the cluster into small segments that can be used for varying workloads. But unlike the traditional mechanism available up to 11.1, which only allows this task by choosing the instances to run on nodes as Preferred & Available and running services using the same architecture, server pools offer a much larger list of attributes which help in the management of resources in a rather simple and transparent way. In server pools, the underlying hosts of the cluster are added (and removed) from the pools much more on-the-fly, and take the burden off the DBA’s shoulders for this task. With just a few parameters to take care of, the whole stack becomes much easier to govern and administer, while still being completely transparent yet powerful to manage all the types of different resources in the RAC clusterware environment, especially when the number of the nodes go beyond two digits.
Server Pool: is managed by the cluster
- Logical division of the cluster into pools of servers
- Applications (including databases) run in one or more server pools
- Managed by crsctl (applications), srvctl (Oracle)
- Defined by 3 attributes (min, max, importance) or a defined list of nodes Min- minimum number of servers (default 0)
- Max – maximum number of servers (default 0 or -1)
- Importance – 0 (least important) to 1000
- Consider this diagram,

In this example we have a 4 node cluster and a server pool named back office to run a database. So whatever servers are in that server pool will run an instance of that server pool. This is seen by the red boxes with two instances in the server pool. There is a front office database where another database is running. It has two instances running in it. One for each server in the server pool. Cluster resources can run on any node in the cluster independent of any of the server pools defined in the cluster.
Now services that are used for our oracle databases work slightly different when working with a policy managed environment. When we create a service it can only run in a server pool. So a service can only be defined in one server pool. Where as a database can be run in multiple server pools. So services are uniform (run on all instances in the pool) or singleton (runs on only one instance in the pool). If it is a singleton service and that instance fails we will fail over that service to another instance in the server pool.
Assigning Servers in the Server Pool:
Servers are assigned in the following order:
- Generic server pool
- User assigned server pool
- Free
Oracle Clusterware uses importance of server pool to determine order
- Fill all server pools in order of importance until they meet their minimum
- Fill all server pools in order of importance until they meet their maximum
- By Default any left over go into FREE

In the example above: There are three server pools. Note the importance front office has the higher importance so two servers are assigned to it first. The Back office is assigned its minimum of one server and if there are any left over LOB is assigned a server and the rest go into the free pool. Hear we have assign max's identified. So if there are available servers in Free back office and front office will be able to grow to their maxs.
What happens if a server fails.

Lets say in backup office a server goes down. Well we have one in free. So the server would be moved out of free into back office and an instance would be started on that server.
If a server leaves the cluster Oracle Clusterware may move servers from one server pool to another only if a server pool falls below its min. It chooses the server to move from:
- A server pool that is less important.
- A server from a server pool of the same importance which has more servers than its min
Practical approach:-
Check the status of server pools using crsctl
[grid@host01 ~]$ crsctl status serverpool -p
NAME=Free
IMPORTANCE=0
MIN_SIZE=0
MAX_SIZE=-1
SERVER_NAMES=
PARENT_POOLS=
EXCLUSIVE_POOLS=
ACL=owner:grid:rwx,pgrp:oinstall:rwx,other::r-xNAME=Generic
IMPORTANCE=0
MIN_SIZE=0
MAX_SIZE=-1
SERVER_NAMES=host01 host02 host03
PARENT_POOLS=
EXCLUSIVE_POOLS=
ACL=owner:grid:r-x,pgrp:oinstall:r-x,other::r-xNAME=ora.orcladm
IMPORTANCE=1
MIN_SIZE=0
MAX_SIZE=-1
SERVER_NAMES=host01 host02 host03
PARENT_POOLS=Generic
EXCLUSIVE_POOLS=
ACL=owner:oracle:rwx,pgrp:oinstall:rwx,other::r--NAME=sp1
IMPORTANCE=2
MIN_SIZE=1
MAX_SIZE=2
SERVER_NAMES=
PARENT_POOLS=
EXCLUSIVE_POOLS=
ACL=owner:grid:rwx,pgrp:oinstall:rwx,other::r
Check the server pools using srvctl
[grid@host01 bin]$ srvctl config serverpool -g Free
Server pool name: Free
Importance: 0, Min: 0, Max: -1
Candidate server names:[grid@host01 bin]$ srvctl config serverpool -g Generic
PRKO-3160 : Server pool Generic is internally managed as part of administrator-
managed database configuration and therefore cannot be queried directly via srvpool
Note:- The MIN_SIZE attribute specifies the cardinality of the resources (database etc) suppose if you have min_size 2, the database instances can run on the two servers in the serverpool. So here its transparent as you are not specifying srvctl add instance –d –i –n etc.
Another Important note:- Adding server pools to clusterware using crsctl (caveat:- using crsctl for adding serverpool will work for non-database resources such as application server etc, for database resources if you are creating serverpool use srvctl instead Read doc here)
For non-database resources,
[grid@host01 ~]$ crsctl add serverpool sp1 -attr "MIN_SIZE=1, MAX_SIZE=1, IMPORTANCE=1"
[grid@host01 ~]$ crsctl add serverpool sp2 -attr "MIN_SIZE=1, MAX_SIZE=1, IMPORTANCE=2"
For database resources create like this
[grid@host01 ~]$ srvctl add srvpool -g sp1 -l 1 -u 2 -i 999 -n host02
[grid@host01 ~]$ srvctl add srvpool -g sp2 -l 1 -u 2 -i 999 -n host03
Note:- Observer the difference, you cannot specify the individual or your wish hosts when using crsctl but when using srvctl you can
[grid@host01 ~]$ crsctl status server -f
NAME=host01
STATE=ONLINE
ACTIVE_POOLS=Free
STATE_DETAILS=NAME=host02
STATE=ONLINE
ACTIVE_POOLS=sp2
STATE_DETAILS=NAME=host03
STATE=ONLINE
ACTIVE_POOLS=sp1
STATE_DETAILS=Host01 is assigned to free pool and rest of the two hosts.
Adding child pools to the serverpools (parentpools)
[grid@host01 Disk1]$ crsctl add serverpool sp_child1 -attr "PARENT_POOLS=sp1,
MIN_SIZE=1, MAX_SIZE=1, IMPORTANCE=2"
In order to effectively use the serverpools aka host resources segregation as stated in the starting of this post, oracle has changed the database options, while using dbca in RAC installation you might found the following screen.

From 11G Release 2 Database when you run DBCA , the third screen in the sequence have this for real application clusters (RAC) installation, Configuration type, Admin or policy managed. so What are they?
Administrator Managed Databases:- (as of now)
Traditionally Oracle had defined or had the DBA’s define which instances run on which servers in a RAC environment. They would clearly define that node1 would run RAC1, and node2 would run RAC2, etc….. Those instances would be tied to those nodes. This is known as Administrator Managed Databases because the instances are being managed by the DBA and the DBA has specifically assigned an instance to a server.
Policy Managed Databases:- (going forward)
In a Policy Managed Databases the DBA specifies the requirements of the database workload. IE. How many instances do we want to run in this workload – Cardinality of the database. With this specified Oracle RAC will try to keep that many instances running for that database. If we need to expand the size all we need to do is expand the cardinality. As long as there are that many servers in the cluster the cluster will keep that many up and running.
- The goal behind Policy Managed Databases is to remove the hard coding of a service to a specific instance or service.
- The database can be associated with a server pool rather than a specific set of nodes. It will decide the minimum and maximum no. of servers needed by that resource (database , service, third party application).
- The database will run on the servers which have been allocated to the serverpool it has been assigned to. (uses min_size to determine where it has to run and how may servers it has to run)
- Since servers allocated to the server pool can change dynamically, this would allow Oracle to dynamically deliver services based on the total no. of servers available to the cluster.
- The database will started on enough servers subject to the availability of the servers. We need not hardcode the servers a database should run on.
- Any instance of the database can run on any node. There is no fixed mapping between instance number and node.
- As servers are freed/added/deleted, they will be allocated to existing pools as per the rules mentioned earlier.
- Example:- In theory
For example, if a cluster consisted of eight nodes in total and supported three RAC databases. Each database would be defined with a minimum and maximum number of servers. Let's assume that
DB1 is defined with a minimum of 4 and a maximum of 6 with an importance of 10,
- DB2 is defined with a minimum of 2 and maximum of 3 and an importance of 7, and
- DB3 is set to a minimum of 2 and maximum of 3 with an importance of 5.
- Initially the 8 nodes could be configured as nodes 1-4 allocated to DB1, nodes 5-6 allocated to DB2 and nodes 7-8 allocated to DB3. If node 3 failed for some reason, the system would allocate node 7 or 8 to DB1 because it has a higher importance than DB3 and a minimum requirement of 4 servers, even though it would cause DB3 to fall below the minimum number of servers. If node 3 is re-enabled it would be allocated immediately to DB3 to bring that database back to its minimum required servers.
- If a 9th node were added to the cluster, it would be assigned to DB1 because of the importance factor and the fact that DB1 has not yet hit its maximum number of servers.
Checking the Database serverpools and modifying them , read below
To check that a database is admin-managed or policy-managed, we can use the command SRVCTL like below:
[grid@host01 Disk1]$ srvctl config database -d orcladm
Database unique name: orcladm
Database name: orcladm
Oracle home: /u01/app/oracle/product/11.2.0/dbhome_1
Oracle user: oracle
Spfile: +FRA/orcladm/spfileorcladm.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: orcladm
Database instances: orcladm1,orcladm2
Disk Groups: FRA
Services:
Database is administrator managed
So we can see that the database ORCLADM is Admin Managed. To convert this database to Policy managed, you can proceed as follows:
[grid@host01 Disk1]$ srvctl stop database -d orcladm
[grid@host01 Disk1]$ srvctl modify database -d orcladm -g sp1
Here sp1 is a server pool over which the database ORCLADM would be running and we can confirm it using the same command SRVCTL: last line say’s that this database is now policy managed
[grid@host01 Disk1]$ srvctl config database -d orcladm
Database unique name: orcladm
Database name: orcladm
Oracle home: /u01/app/oracle/product/11.2.0/dbhome_1
Oracle user: oracle
Spfile: +FRA/orcladm/spfileorcladm.ora
Domain:
Start options: open
Stop options: immediate
Database role: PRIMARY
Management policy: AUTOMATIC
Server pools: sp1
Database instances:
Disk Groups: FRA
Services:
Database is policy managed
But how to control, the services pointing to specific nodes of the serverpool? by using –c option in srvctl add service.
Finally, creating RAC services, First look at the table below for adding a service using srvctl,
srvctl add service -h
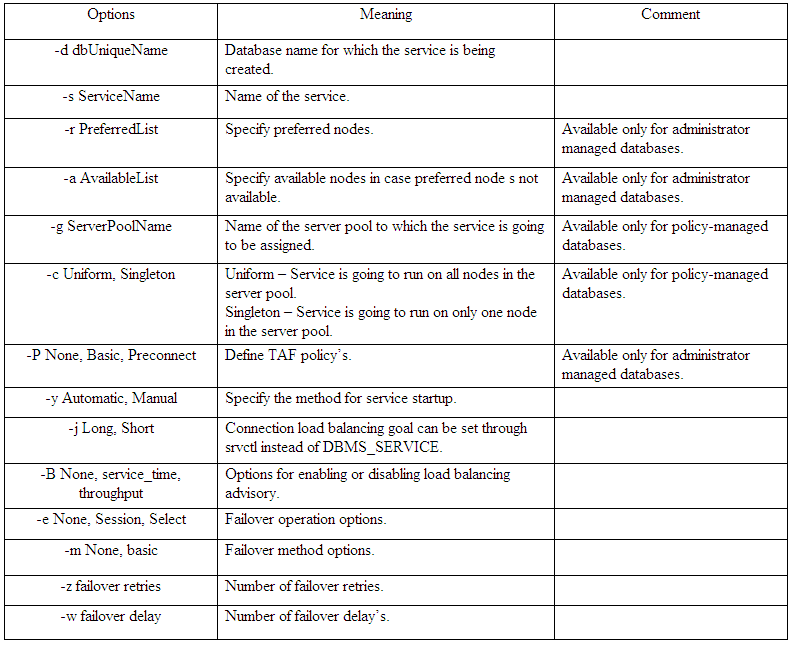
Did you see the options serverpool, uniform, singleton, this two options states the service nature, for policy based databases you will not specify the available and preferred instances, instead you will opt for above two. (See last column)
For example:-
If you want to create a service “all” that should run in sp1 (serverpool) on all nodes. the command should be
srvctl add service –d orcladm –s all –g sp1 –c uniform …
If you want to create a service “one” that should run in sp1(serverpool) on only one node, the command should be
srvctl add service –d orcladm –s all –g sp1 –c singleton ..
Note above I haven’t specified any available or preferred node as orcladm is no more admin managed DB.
Some other notes to DBA,
SIDs are DYNAMIC
- DBA scripts may have to be adjusted
- Environment variables settings in profiles will have to check the current sid
- Directories for LOG files will change over restarts
“Pin” Nodes
- Forces Oracle Clusterware to maintain the same
- Node number when restarted (which maintains SID) Automatically done on upgrades
- Required when running pre-11g Release 2 versions in the cluster
- On upgrade, the nodes will be “pinned”
crsctl pin css -n nodename
Thanks
Geek DBA
References:-
Server Pool - Oracle 11g RAC New Feature
Administering Oracle Clusterware
[…] Read here […]
Nice & precise piece of information very useful. Thank you
Oracle 11g RAC Interview Questions:
From In this 37 and 38 are same answers showing Is this Right for both questions.
Otherwise send me the correct answer
[…] If you have not read server pool concept so far please read it from here. […]
[…] If you have not read server pool concept so far please read it from here. […]